多模态大模型,到底有多“嘴硬”?
浙江大学联合阿里巴巴、香港城市大学、密歇根大学的研究团队做了一个很直接的实验:
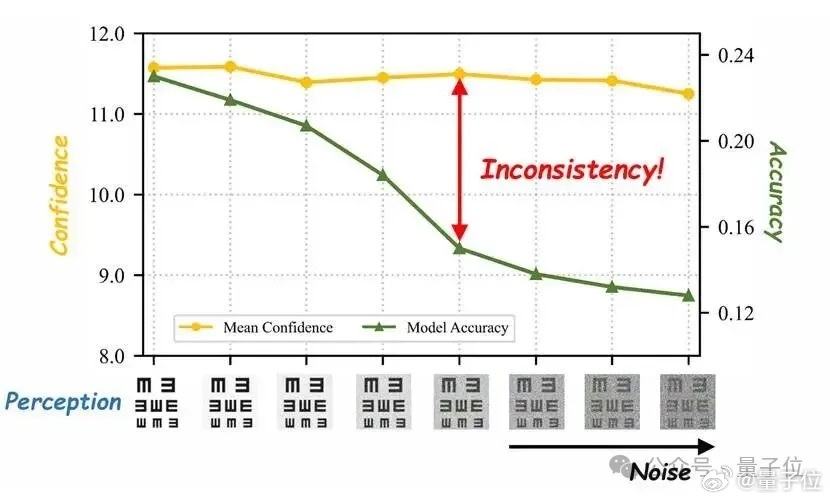
把输入图像从清晰状态一路加噪到接近不可辨认,同时持续监测模型的准确率与置信度。
结果是,准确率断崖式下跌,但置信度几乎不动。也就是说,图像已经看不清了,模型仍然会高置信度地给出答案。
这类“盲目自信”,正是多模态大模型在复杂视觉推理中产生幻觉和误判的重要根源。针对这一问题,研究团队提出了CA-TTS(Confidence-Aware Test-Time Scaling)框架:先通过置信度驱动的强化学习校准模型的自我评估能力,再把校准后的置信度转化为推理阶段的资源分配信号。
效果也很直接:在四个主流视觉推理基准上,CA-TTS全面达到SOTA,平均超越现有最优方法8.8%。其中,在Math-Vision上,准确率从基线的23.0%提升到42.4%。论文已被CVPR 2026接收。网页链接