DeepSeek的推理又提速了,这次的关键不是算力堆上去,而是算法更聪明了。百度在 SGLang 里加了一套多令牌预测机制(MTP),让模型一次能连说几句话,而不是一口气只挤出一个 token。
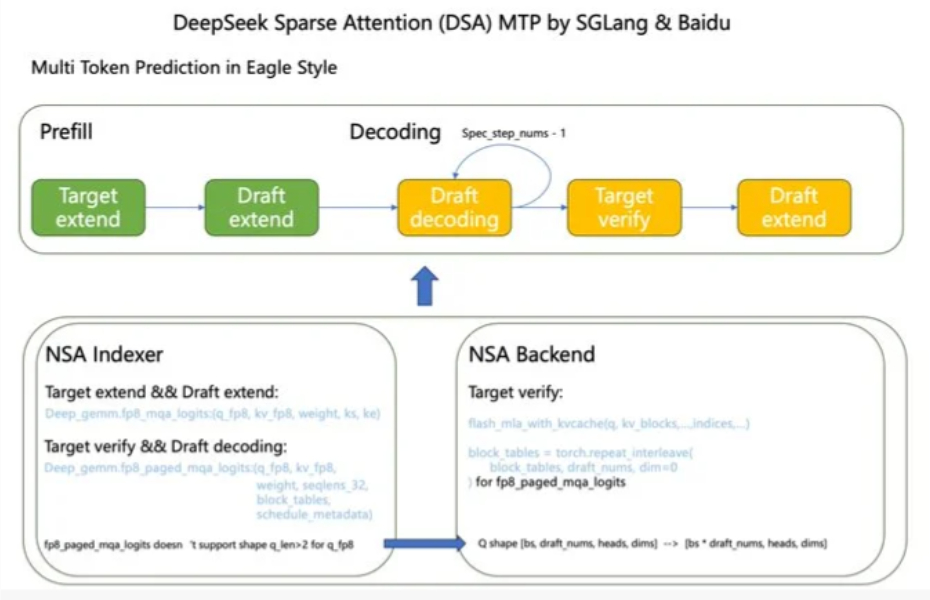
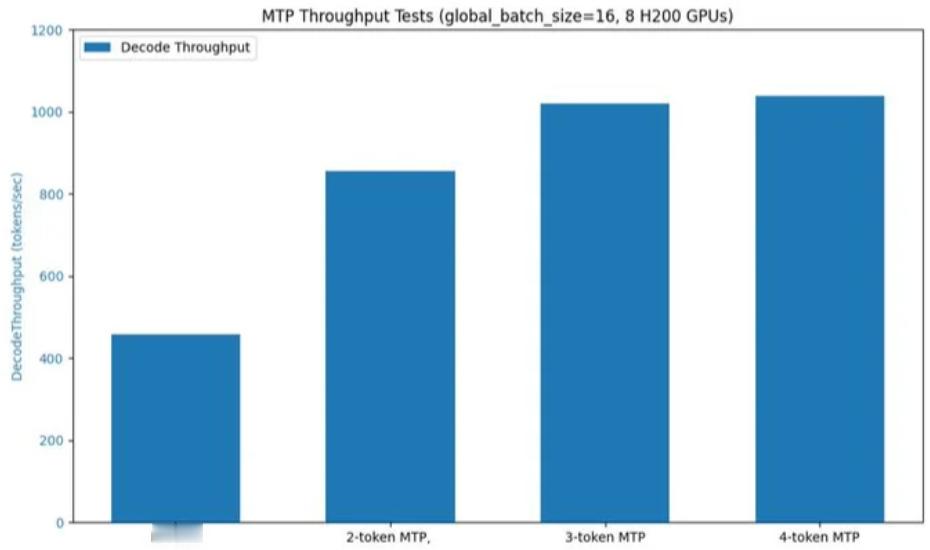
结果就是:同样的 GPU,吞吐量翻倍还多。3-token 模式的表现几乎碾压传统推理流程。对开发者来说,这意味着未来的大模型不只是更强,而是更快,真正从算力竞争,走向算法效率的较量。
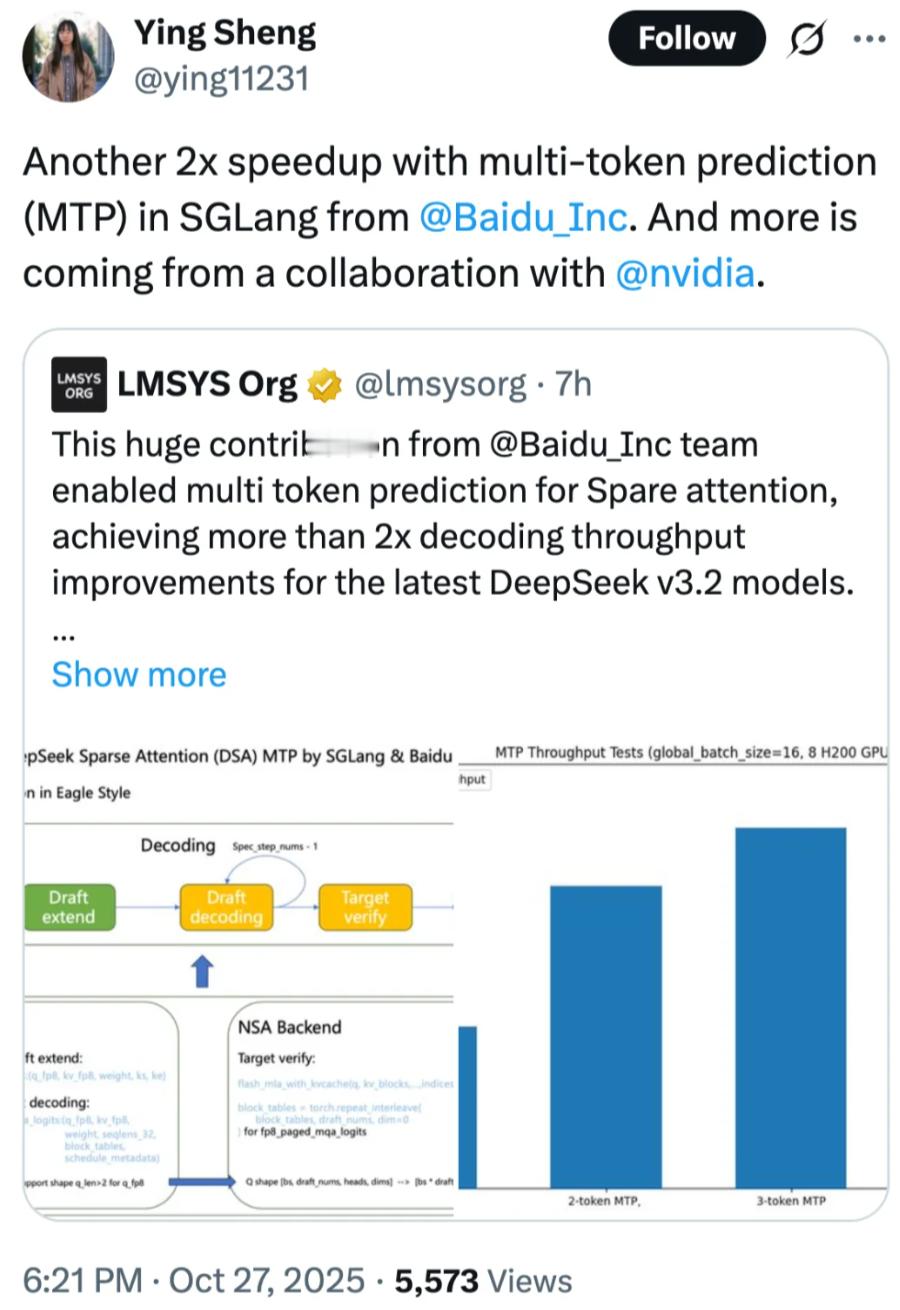
DeepSeek的推理又提速了,这次的关键不是算力堆上去,而是算法更聪明了。百度在 SGLang 里加了一套多令牌预测机制(MTP),让模型一次能连说几句话,而不是一口气只挤出一个 token。
结果就是:同样的 GPU,吞吐量翻倍还多。3-token 模式的表现几乎碾压传统推理流程。对开发者来说,这意味着未来的大模型不只是更强,而是更快,真正从算力竞争,走向算法效率的较量。