理解DeepSeek-OCR的震撼成果,需要OCR、token的基础知识,还和“高达”有关
我看了DeepSeek-OCR的论文,很有意思。不少报导说,它用10倍压缩率,还有97%的解码准确率。其实这些名词大多数人的理解都是似是而非的,10倍压缩什么意思,97%如何定义,压缩的是什么,仔细问都是稀里糊涂的。
一。DeepSeek-OCR与几种识别模式
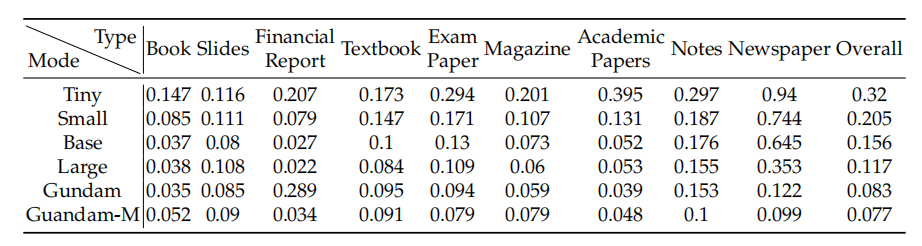
DeepSeek-OCR,顾名思义,就是用来做OCR(光学字符识别)的一个神经网络模型。如图,这种输入的OCR图,可以是书、演示文档、财经报告、教科书、试卷、杂志、学术论文、便条、报纸,特性各有不同,但原始信息就是是带格式的文字。要把这些文本信息识别出来。业界把分子式、几何图形、图表这些规整的图,也找到办法,用文本来表示,也可以识别。
不同类型的图难度各有不同,如书的字就明显比报纸的字少。DeepSeek-OCR有几种模式,能力从“tiny”到“高达”(Gundam),由弱到强(但计算代价从少到多)。图中数据是“edit distance”,可以理解为错误率,平均对每个字符要处理多少次“插入、删除、替换”的次数,能精确还原出原始信息。如果是0.1,人们大致能理解,相当于OCR出来的90%文本是对的,错的也是标点符号这类不太关键的。
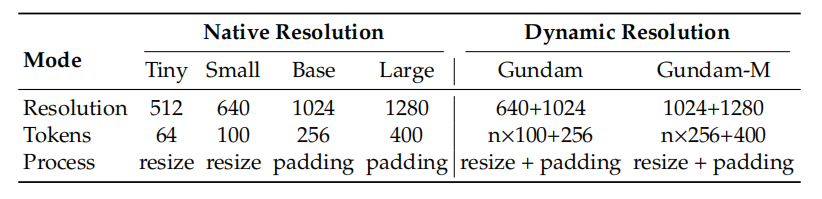
图二,模式强弱,是用内部的“vision token”数量来代表的。如Tiny模式是一张图缩放成512*512的图,然后处理成变成64个token。Small模式是先变640*640的图,变成100个token。这两个模式的图是直接拉升缩放,字可能会长宽变形。
Base模式是把OCR图先变成1024*1024,用填充缩放(字没有长宽变形),然后处理成256个token。Large模式是弄成1280*1280的图,做出400个token。
一页书的字少,用tiny模式64个token就能认出85%(0.147的edit distance),但报纸上的字太多了,tiny模式94%的错误率,几乎啥也认不出。报纸用400个token的large模式,也还是有35.3%错了,很不好读。
报纸要用“高达”模式(意指机器人拆分),这种模式是把个图切成n个Small模式的小图(640*640,每图100个token),然后有一个1024*1024的全景图。用的token多了,就能识别成功,错误率12.2%基本能认了。最强的是高达-M模式,切成n个Base模式的图,加一个1280*1280的全景图,错误率最小。
很妙的是,DeepSeek-OCR可以用OpenCV作简单的图像预处理,判断其中的文字多少,选择合适的模式来处理OCR图。如对图作“边缘检测” (如Canny oprator),看边缘点的数量,占整图的比例。如果少于3%,就没有多少字,tiny模式就能处理好(跑得快)。如果多于8%,就得用高达模式了。
二.解释vision token、10倍压缩率
听大模型知识多了,很多人知道token。但其实没太多人知道token到底是什么,往往理解成一个字或一个词,大差不差。其实最直接的计算机理解,它是一个很多维的“向量”。如DeepSeek V3.1/R1,每个token就有7168维。这么多维才能代表token在语义中多种丰富的意义与关联。我们输入给大模型的“提示词”有1000个token,第一步就会变成1000*7168的矩阵,放得很大。这种token是tokenizer(分词算法)给出的。
在DeepSeek-OCR里面,一个token是512维,也有很丰富的含义(所以才有这么厉害的OCR能力)。这种token是vison token,是一个图像处理算法给出来的。如输入的是512*512的图片,用一个确定算法,就变成64个token。其实视觉大模型,和文字大模型,就是“变出token”这步区别大,内部处理的都是一堆token的矩阵计算,核心技术是相通的。
再来说下10倍“压缩率”。
按论文里说的“一图胜千言”,可以粗粗理解为将1000个字符token,处理成一张图像;然后把这图,用DeepSeek-OCR里面的Small模式,经过DeepEncoder的变成100个视觉Token;再用对应的Decoder解码出来1000个字符token,其中有97%的字符是正确的。从100个token变出最终的1000个token,这是10倍的压缩率。
但要注意,如果从文本大小的意义上看,其实并没压缩。因为1个token就有512维,那有5万多个数据了,比1000个字符占的存储空间大多了。
它真正的意义,是在大模型处理上的,token数量变少了意义很大。我们日常用大模型的时候,如果输入给大模型的“提示词”有1000个token,第一步就会变成1000*7168的矩阵。然后大模型的大招是“自注意力”,要对这1000个token互相都建立“关联”,是1000*1000的平方关系。token越多,需要的算力平方增长。
而DeepSeek-OCR的技术,可以把1000个文字token先用视觉方法,处理成100个视觉token,再来搞平方关系的“自注意力”,代价也不大了。这在大模型长文本处理上,可能很有潜力。这个10倍的压缩率,算法意义就很大。
当然它现在还没有这么做,只是用64-400个视觉token来做图片的OCR。用这么少的token,就能完成很复杂的OCR任务,说明了视觉token体系很有潜力,真的能代表复杂的人类文本。
这确实有些不可思议,人类文本图片那么多种,用少数几百个token就能抽象代表一张图,差错率很小。说实在是很震撼的成果。