今天去元戎启行的发布会上课了!看看我学到了啥👀
发布了 IO 2.0 平台 + VLA 大模型。IO 2.0相当于一个“拼装积木”,能支持不同车企的需求,不管是带激光雷达还是纯视觉,都能适配。
VLA是啥?
全称 Vision-Language-Action(视觉-语言-动作)。以前的自动驾驶更像“看图做题”:直接把像素转成操作。VLA中间加了一步“语言/语义理解”,就像先读题、理解,再答题。好处是——更聪明、更可解释。
官方展示四个场景都直观感受:
1️⃣能理解“公交车遮挡、桥洞”这种复杂场景,提前减速更稳妥;
2️⃣能认出奇奇怪怪的障碍,比如超载小货、锥桶;
3️⃣能看懂交通标牌上的文字(潮汐车道/公交专用道);
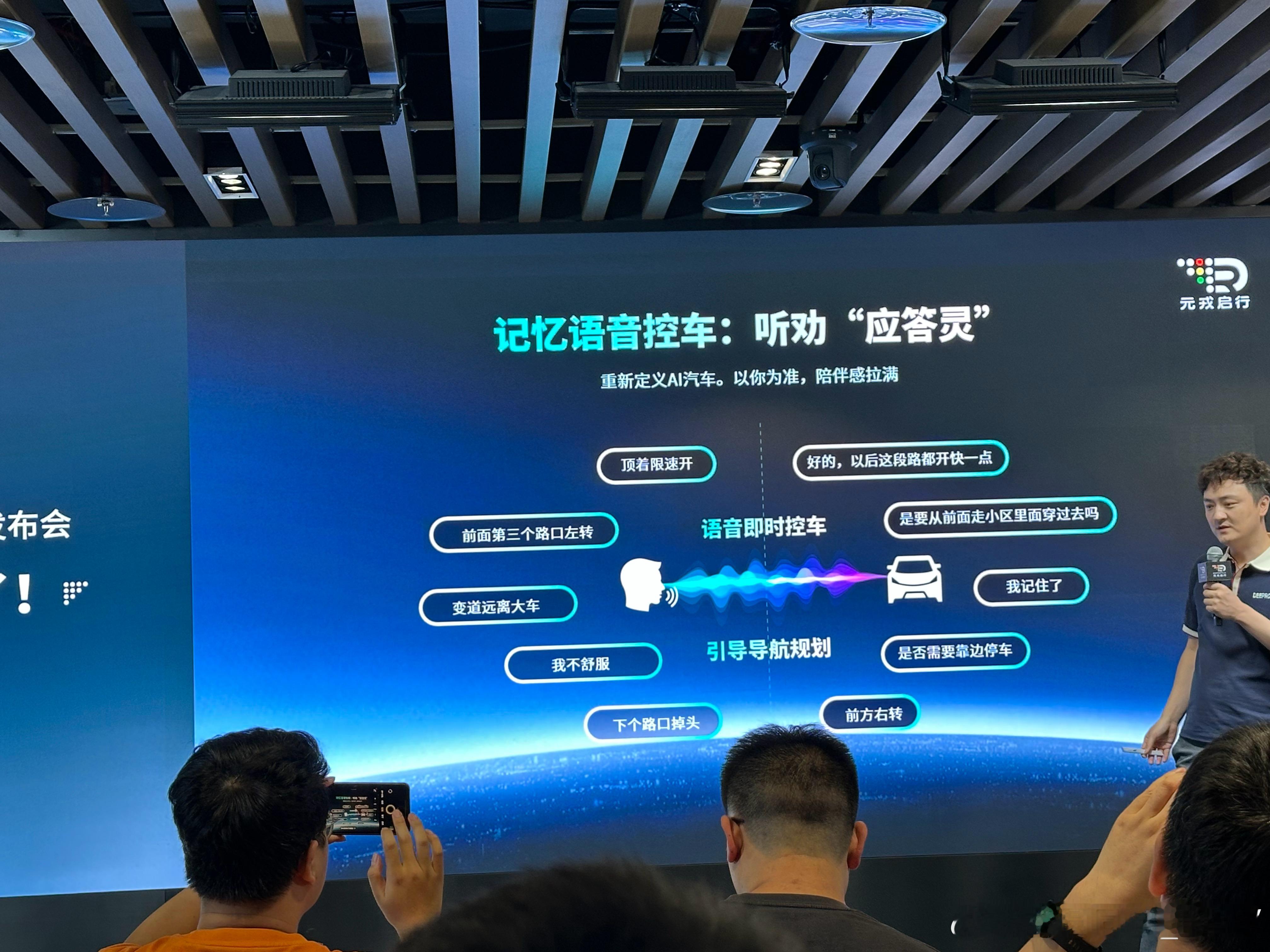
4️⃣语音助手能连着聊,还能记住你的习惯。
为什么要加“语言”层?
可解释,方便回放“为啥这么开”;能处理以前没见过的东西,
中国路况标牌太多文字,不懂字就玩不转;
可以把“常识”编码进去,遇到遮挡也能更稳。
落地情况:
已经有10+车型定点,量产车快10万台跑在路上。未来会继续铺在乘用车里,同时带着Robotaxi往前走。
我的小疑问[思考]
VLA会不会更吃算力?多芯片怎么分工?
“更保守”的判断怎么平衡不怂不莽?
一句话总结:这套东西不是单纯堆参数,而是让车子从“看图秒答”变成“读懂题再答”,更接近人类驾驶逻辑。对中国这种复杂路况来说,是条挺现实的路。
实际表现如何,我明天亲自给宝宝们试一下再云汇报~
元戎启行元戎启行deeproute