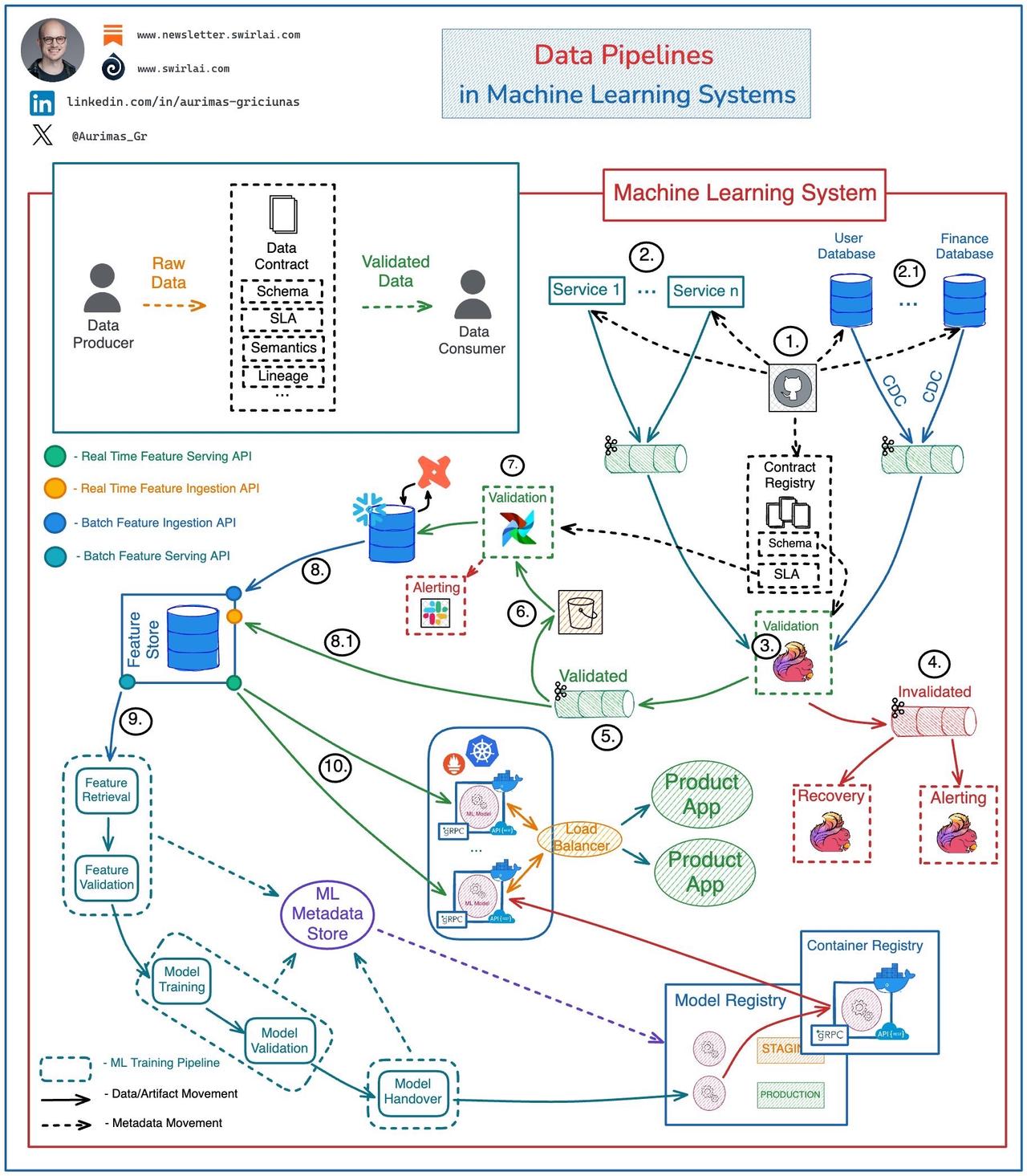
𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝗶𝗻 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀可能会变得复杂,这是有原因的👇 确保 ML 训练和推理管道上游的数据质量和完整性至关重要,如果在下游系统中尝试这样做,则在大规模工作时会导致不可避免的失败。 在数据湖或 LakeHouse 层有大量工作要做。 𝗦𝗲𝗲 𝘁𝗵𝗲 𝗲𝘅𝗮𝗺𝗽𝗹𝗲 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗯𝗲𝗹𝗼𝘄 。 𝘌𝘹𝘢𝘮𝘱𝘭𝘦 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦 𝘧𝘰𝘳 𝘢 𝘱𝘳𝘰𝘥𝘶𝘤𝘵𝘪𝘰𝘯 𝘨𝘳𝘢𝘥𝘦 𝘦𝘯𝘥 - 𝘵𝘰 - 𝘦𝘯𝘥 𝘥𝘢𝘵𝘢 𝘧𝘭𝘰𝘸 : 𝟭 :模式变更在版本控制中实施,一旦获得批准,它们就会被推送到生成数据的应用程序、保存数据的数据库和中央数据合同注册表。 应用程序将生成的数据推送到 Kafka 主题: 𝟮 :应用服务直接发出的事件。 👉这还包括物联网车队和网站活动跟踪。 𝟮 . 𝟭 :CDC 流的原始数据主题。 𝟯 :Flink 应用程序使用原始数据流中的数据,并根据合同注册表中的模式对其进行验证。 𝟰 :不符合合同的数据被推送到死信主题。 𝟱 :符合合同的数据被推送到已验证数据主题。 𝟲 :来自已验证数据主题的数据被推送到对象存储以进行额外的验证。 𝟳 :按照计划,对象存储中的数据将根据数据合同中的附加 SLA 进行验证,然后推送到数据仓库进行转换和建模,以用于分析目的。 𝟴 :建模和整理的数据被推送到特征存储系统,以进行进一步的特征工程。 𝟴 . 𝟭 :实时特征直接从已验证数据主题 (5) 提取到特征存储中。 👉确保这里的数据质量很复杂,因为针对 SLA 的检查很难执行。 𝟵 :机器学习训练管道中使用高质量数据。 𝟭𝟬 :相同的数据用于推理中的特征服务。 注意:机器学习系统受到其他数据相关问题的困扰,例如数据漂移和概念漂移。这些是隐性故障,虽然可以监控,但我们无法将其纳入数据合约。 告诉我你的想法! 👇 AI MachineLearning DataEngineering 编程严选网