『CGWORLD + digital video」vol.319(2025年3月刊)』
MARZA ANIMATION PLANET系列专访(节选)
*内含未经渲染的模型及工作文件展示
*感谢私信投稿!
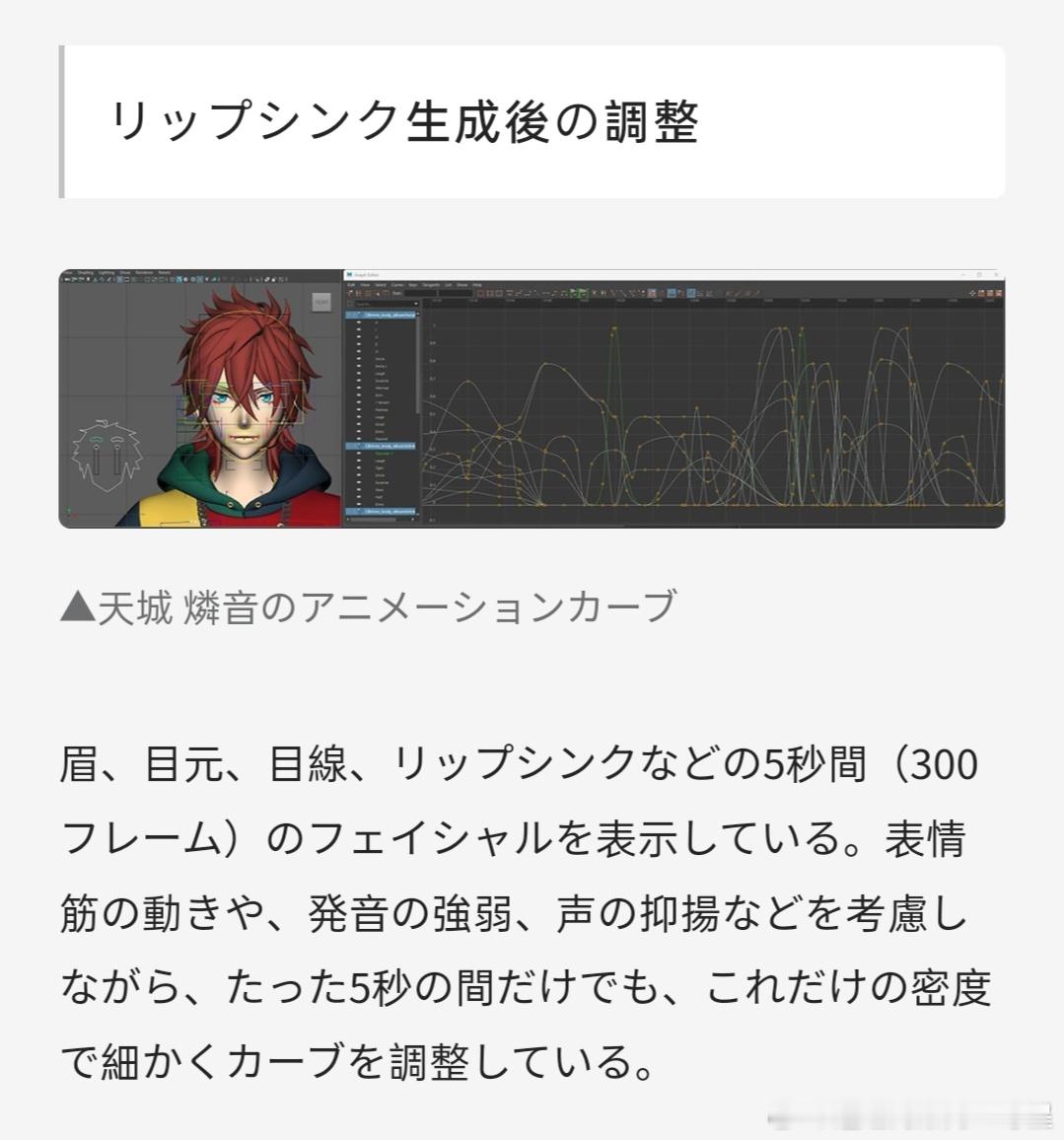
【口型数据生成后的调整】
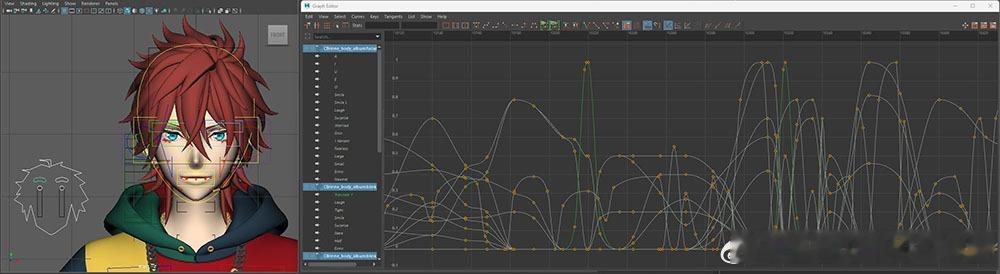
(p1-燐音的动画曲线)
图中展示了五秒(300帧)包括眉毛、眼睛、视线以及口型的面部数据。要全方位考虑面部肌肉的变化、发音的强弱、声音的抑扬等细节,仅仅五秒,就需要使用大量的曲线来进行微调。
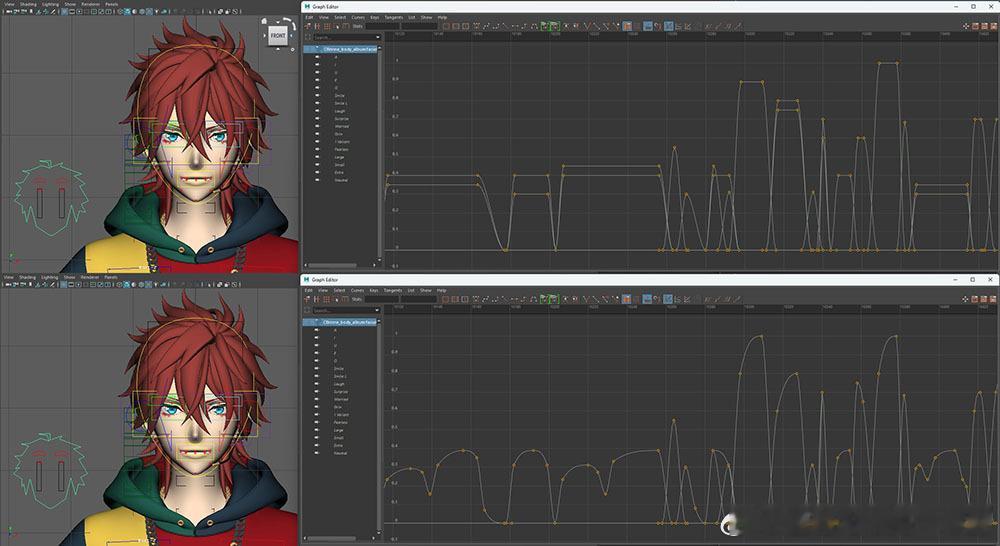
(p2-图为仅显示口型的工作栏状态。【上】为使用Lip Sync GUI配置好各个母音锚点,粗略设定了强弱的状态。【下】为继续编辑各个锚点的曲线,制作好了更细致的强弱和抑扬的状态。)
「因为歌唱部分的口型是以正式歌曲为基准进行设定,又没有仅人声的音源,所以声音解析软件派不上用场。就算使用解析软件,也会给每一帧打上关键帧,修正工作反而会变多。因此我们认为,想要0失误地完成口型的制作,最快速且正确的做法就是从一开始便采用实听和手动的做法来进行工作。」(木下氏)