🔻让我们继续读代码:Deepseek 的 Smallpond,基于 DuckDB 和 3FS 的数据处理框架。
🔻从本质上讲,smallpond是一个轻量级数据处理框架,旨在处理海量数据集。想想 PB 级的数据。它利用DuckDB(进程内分析数据库)和3FS (分布式文件系统)的强大功能来实现高性能和可扩展性。
🔻但为什么这对 MoE 模型来说很有趣呢?因为 MoE 因其庞大的规模而臭名昭著。使用这些模型进行训练甚至推理都需要高效的数据管道来满足需求。Smallpond旨在提供这种效率。
🔻MoE 模型的核心是拥有只针对特定输入而激活的专业专家。这意味着你需要有效地加载和预处理数据(将正确的数据提供给正确的专家至关重要)、分片数据(将数据分布在多个设备/节点上进行并行处理)、汇总结果(结合不同专家的输出来得出最终的预测),Smallpond勇敢面对这些挑战。
🔻DuckDB 是smallpond速度的秘密武器。它是一个进程内 OLAP 数据库,这意味着它可以直接对数据执行复杂的分析查询,而无需单独的数据库服务器开销。其亮点是:
🔹列式存储: DuckDB 将数据存储在列中,这对于只需要访问部分列的分析查询非常理想。这可以减少 I/O 并提高性能。
🔹矢量化执行: DuckDB 以批量(矢量)而不是逐行处理数据,这大大加快了查询执行速度。
🔹查询优化: DuckDB 具有复杂的查询优化器,可以重写查询以提高性能。
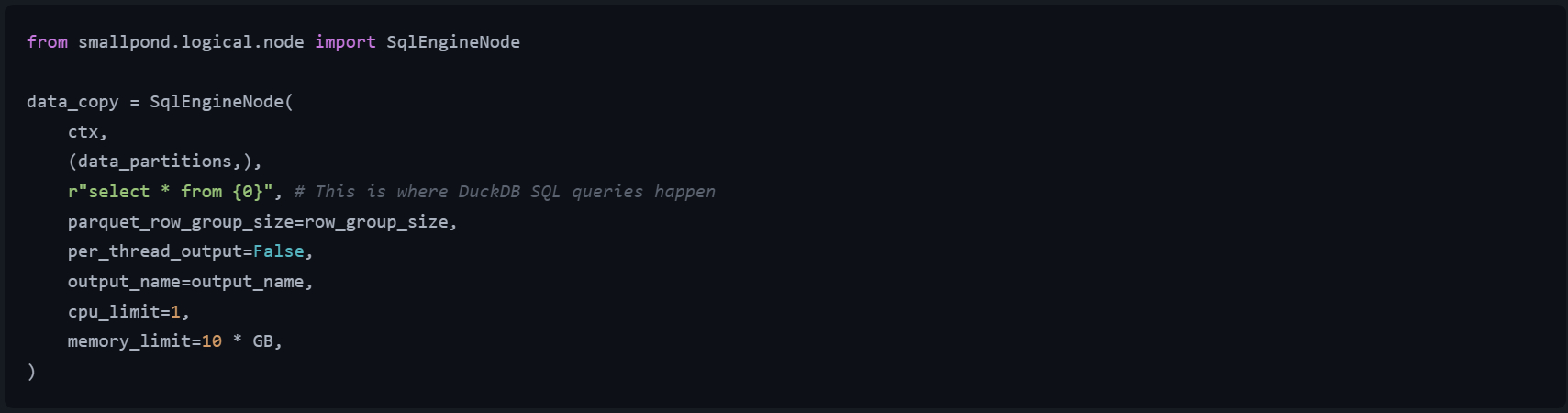
🔻图1是smallpond使用 DuckDB 的方式(来自 enchmarks/file_io_benchmark.py),此代码片段展示了smallpond如何SqlEngineNode对数据分区执行 SQL 查询。r"select * from {0}"是 DuckDB SQL 查询的占位符。
🔻Smallpond依靠共享文件系统 3FS 来提供可扩展且可靠的存储层。3FS 旨在处理 PB 级数据集并提供高吞吐量的数据访问。其亮点是:
🔹分布式存储: 3FS 将数据分布在多个存储节点上,提供可扩展性和容错能力。
🔹对象存储: 3FS 使用对象存储,非常适合存储大文件。
🔹数据局部性: 3FS 尝试将数据放置在靠近需要它的计算节点的位置,从而减少网络延迟。
🔻smallpond中的一些关键创新使其特别适合 MoE 工作负载:
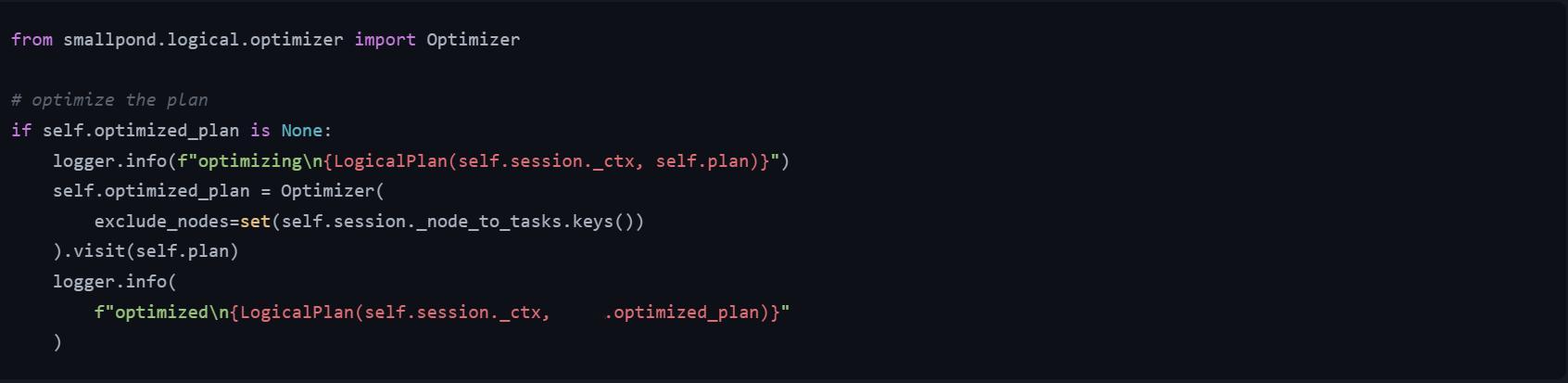
🔹逻辑计划优化: Smallpond使用逻辑计划优化器来重写查询并提高性能。它允许用高级语言 (SQL) 表达复杂的数据转换,并让优化器找出执行它们的最佳方式。优化器使用LogicalPlanVisitor来遍历和修改计划(代码片段见图2)
🔹基于任务的执行: Smallpond将数据处理管道分解为一系列独立的任务。这允许并行执行和容错。如果某个任务失败,则可以重试而不影响其他任务。
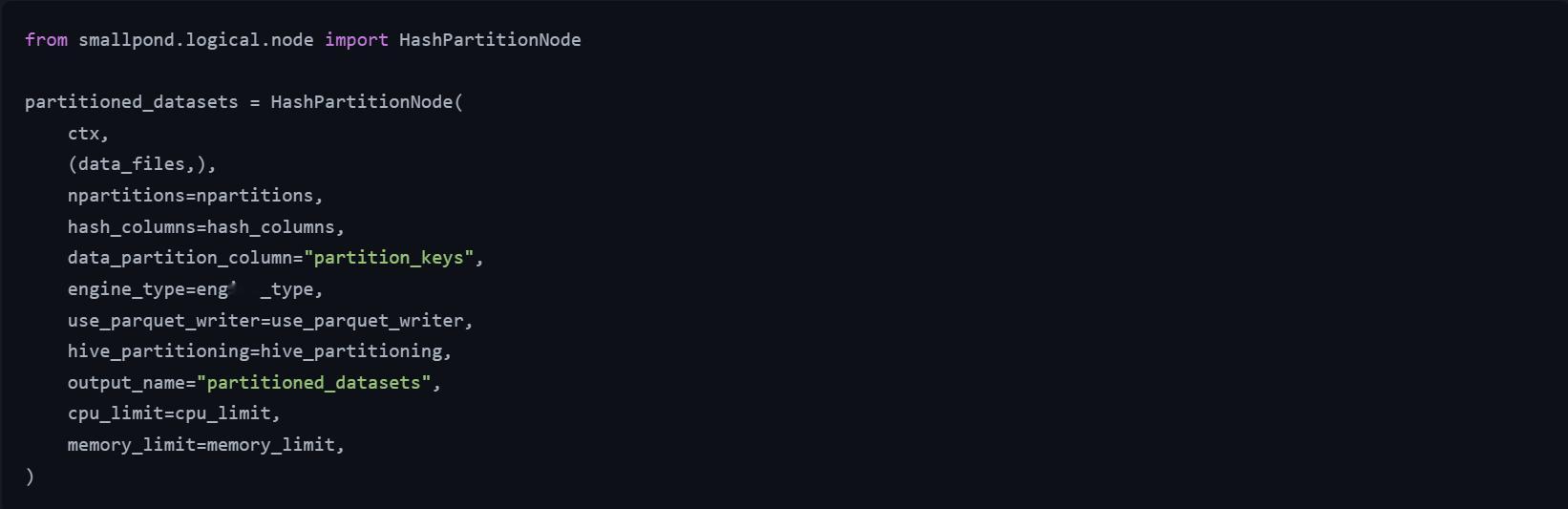
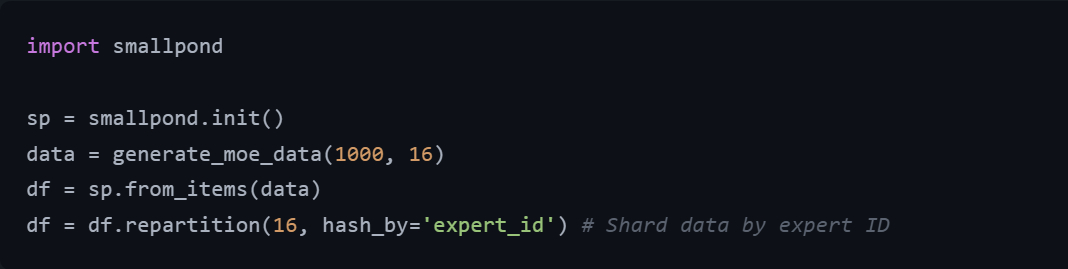
🔹数据分区: Smallpond提供灵活的数据分区功能,能够根据不同的标准对数据进行分片。可以将数据分布在多个设备上,并确保每个专家只收到其所需的数据,比如哈希分区(根据列的哈希值对数据进行分片,例如hash_by='expert_id',代码片段见图3,来自benchmarks/hash_partition_benchmark.py)、范围分区(根据一系列值,例如by='expert_id'对数据进行分片)、均匀分布分区(在各个分区之间均匀分布数据,例如repartition(10)。)
🔹内存管理: Smallpond使用内存分配器(jemalloc 或 mimalloc)来高效管理内存使用。这对于 MoE 模型来说至关重要,因为它们会消耗大量内存。
🔹推测执行: Smallpond支持推测执行,这意味着它可以启动同一任务的多个实例,并使用第一个实例的结果来完成。这有助于减少落后任务(慢速任务)的影响并提高整体性能(代码片段见图4)
🔻让我们看一些代码示例来说明Smallpond如何针对 MoE 模型进行定制:
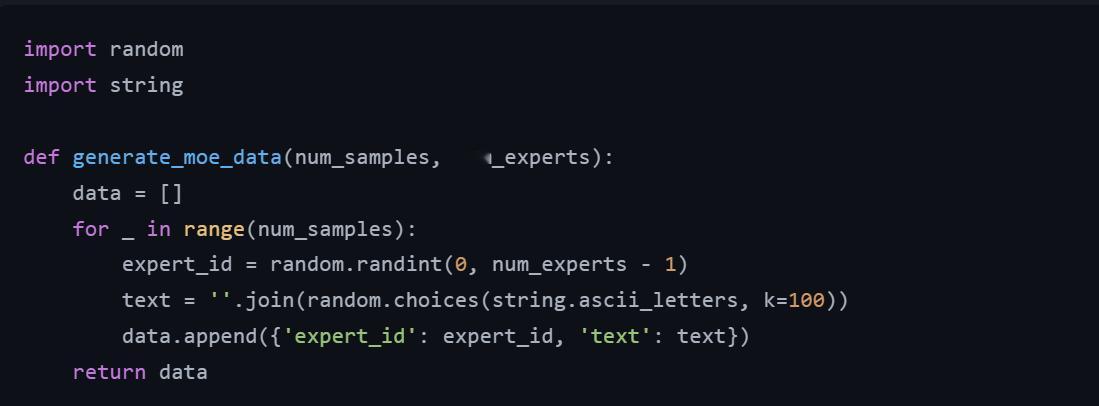
🔹生成 MoE 训练数据:图5
🔹为专家划分数据:图6
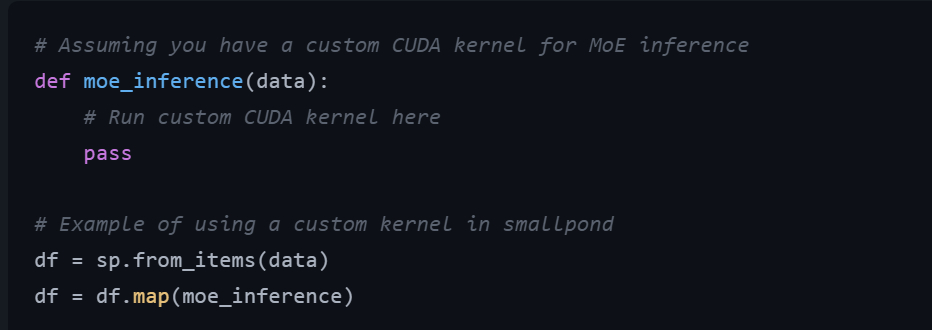
🔹集成自定义内核(假设):图7
🔻因此,传统数据处理框架通常依赖于单一的整体式缓存,这在处理大型 MoE 模型时可能会成为瓶颈。Smallpond 采用了DeepSeek 正在开发的一些尖端技术,尤其是围绕张量内存访问 (TMA) 和交错缓存的技术,有助于克服这一瓶颈并实现更高的性能,为 MoE 模型构建高效的数据管道。Smallpond 使用 DuckDB、3FS、逻辑计划优化、基于任务的执行和灵活的数据分区功能,可扩展以处理 PB 级数据集!非常适合处理 MoE 工作负载的挑战。
🔻Deepseek 在一个由 50 个计算节点和 25 个存储节点组成的运行3FS 的集群上使用GraySort 基准测试(脚本)对 smallpond 进行了评估。基准测试在 30 分 14 秒内对 110.5TiB 数据进行了排序,平均吞吐量为 3.66TiB/分钟。
🔻省流:想象一下把,Deepseek 为了大模型甚至自己开发了一个文件系统和数据处理框架?然后,这件事实际上是他们 2019 年就在做的?(图8)
🔻从底层开始才是正道,你除了张开嘴说“哇喔”,你还能做什么?