读了一下deepseek的论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。DeepSeek最核心的两个创新,一个是采用纯强化学习跳过监督微调,一个是采用蒸馏技术把大模型提炼成小模型节省算力。(Distillation这个词实在是印象太深刻了。)DeepSeek最有趣的是它的“啊哈时刻”,这是它和所有其他AI最典型的区别特征。
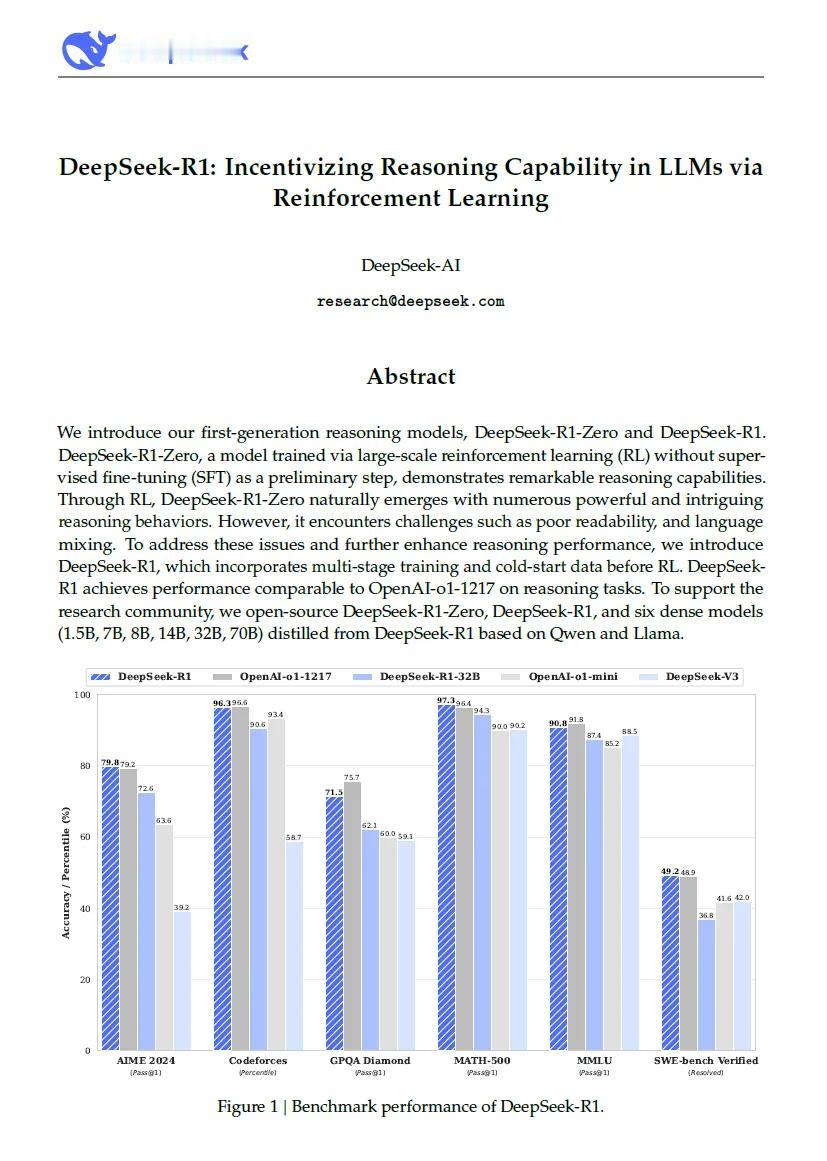

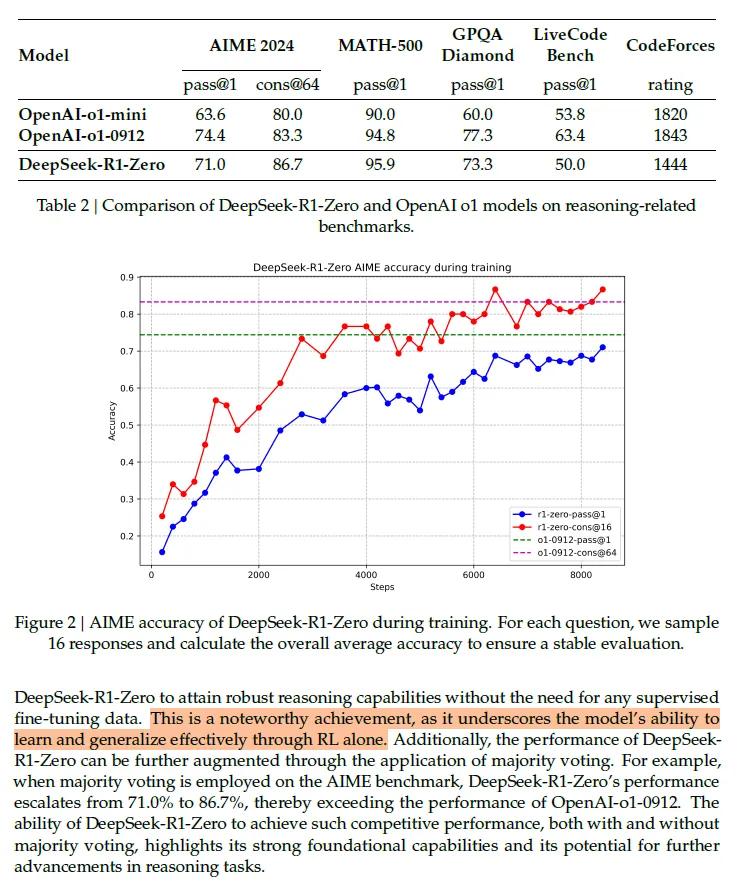
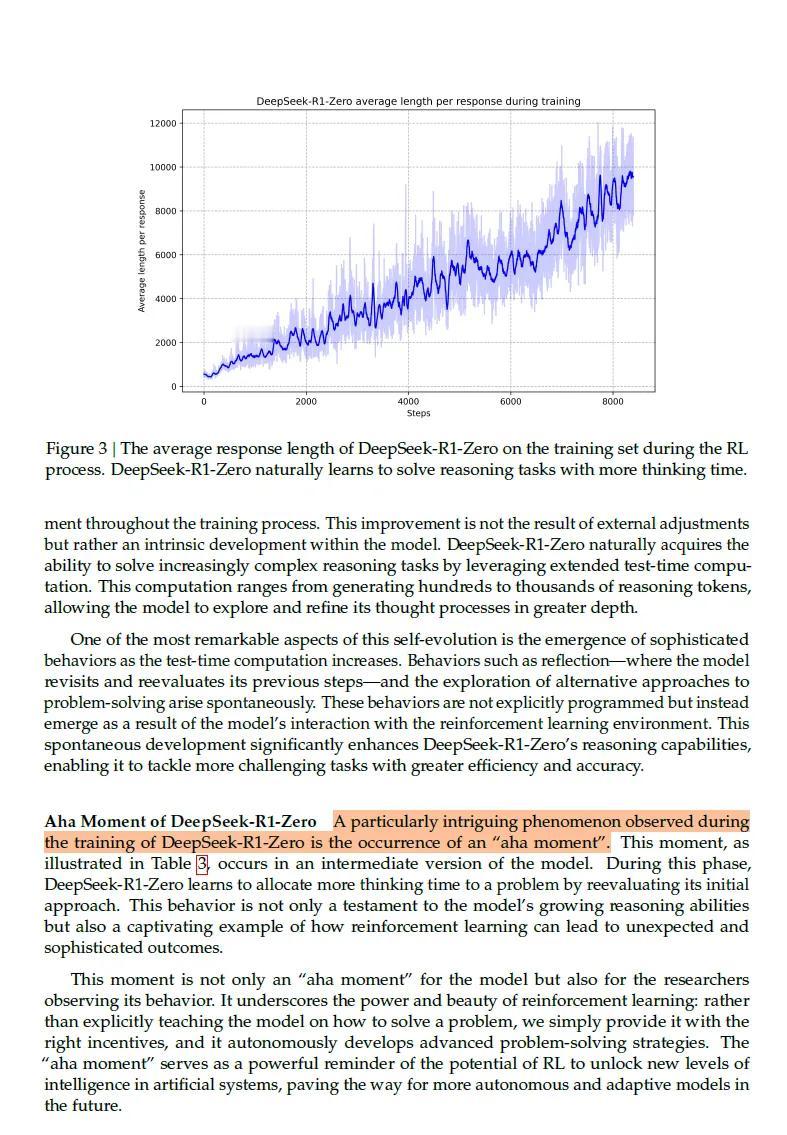

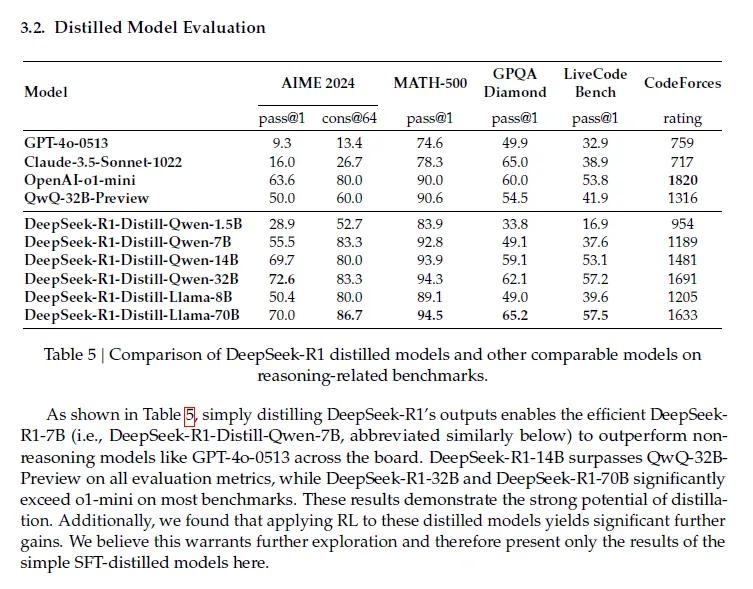
读了一下deepseek的论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》。DeepSeek最核心的两个创新,一个是采用纯强化学习跳过监督微调,一个是采用蒸馏技术把大模型提炼成小模型节省算力。(Distillation这个词实在是印象太深刻了。)DeepSeek最有趣的是它的“啊哈时刻”,这是它和所有其他AI最典型的区别特征。

作者最新文章
热门分类
财经TOP
财经最新文章