Ollama是一个 开源、轻量级的工具,专为在本地计算机上运行大型语言模型(LLM)而设计。你可以把它理解为一个本地AI模型的“应用商店”和“运行环境”,让你能像使用普通软件一样,轻松地在自己的电脑上体验和利用各种AI模型,而无需依赖云端服务或具备深厚的技术背景。
官方网址: https://ollama.com
Ollama核心特点本地运行,保护隐私: 所有数据都在你自己的计算机上处理,无需上传到云端,有效保护了个人或企业的数据隐私和安全。
操作简单,开箱即用: 无论是通过简洁的命令行,还是新推出的图形界面桌面应用,你都可以轻松完成模型的下载、安装和运行,大大降低了AI的使用门槛。
硬件要求灵活: 它不仅支持GPU加速(NVIDIA、AMD、Apple Metal),也能在仅有CPU的环境下运行,让更多用户能在现有设备上体验AI。
模型生态丰富: 支持运行包括Llama 3、DeepSeek-R1、Phi 4、Gemma、Mistral等在内的众多主流开源大模型。
提供API,便于集成: Ollama内置了RESTful API,方便开发者将其集成到自己的应用、聊天机器人或工作流中。
它能做什么?无论是技术爱好者还是普通用户,都能从Ollama中找到适合自己的用法:
对于普通用户:你可以像使用其他聊天软件一样,通过Ollama的桌面应用与AI模型对话。它还支持直接拖拽PDF、文本或图片文件,让AI帮你分析内容。
对于开发者和企业:可以基于Ollama快速搭建本地知识库、智能客服助手,或在没有网络的环境下进行AI应用开发。通过其API,你能用Python等语言轻松调用模型能力。
安装 Ollama安装 Ollama 工具,主要通过官方的安装方式: https://ollama.com/download/mac
官方提供两种安装方式,通过命令行安装和通过下载安装。
通过命令行安装通过命令行安装需要打开 Terminal 终端,并输入以下命令
curl -fsSL https://ollama.com/install.sh | sh
命令执行成功后,会提示安装成功。
通过下载安装通过下载安装需要访问 Ollama 的下载页面 https://ollama.com/download/
点击 Download for macOS 进行下载

下载完成后,和普通的软件一样,双击安装即可
测试安装是否成功测试安装是否成功,以运行在Mac系统为例,可以通过 Mac 的应用启动图标启动 Ollama。
启动后会在右上角显示一个图标

也可以通过命令行进行测试
ollama
模型仓库-镜像-服务关系如果使用过 Docker ,会发现 Ollama 的相关概念以及命令基本类似。
Ollama 整体的结构也是由 模型仓库 、 模型镜像 和 模型服务 组成,他们的关系如下:

• 模型仓库:模型仓库存储了所有可用的模型镜像。
• 模型镜像:模型镜像是由大模型文件按照指定的格式打包的制品。
• 模型服务:模型服务是由模型镜像启动的进程,用于处理用户请求。
查找模型Ollama 官方提供了支持的模型列表 https://ollama.com/search

查询到合适的模型类型后,还需要进入到模型详情中确认具体的模型名称、
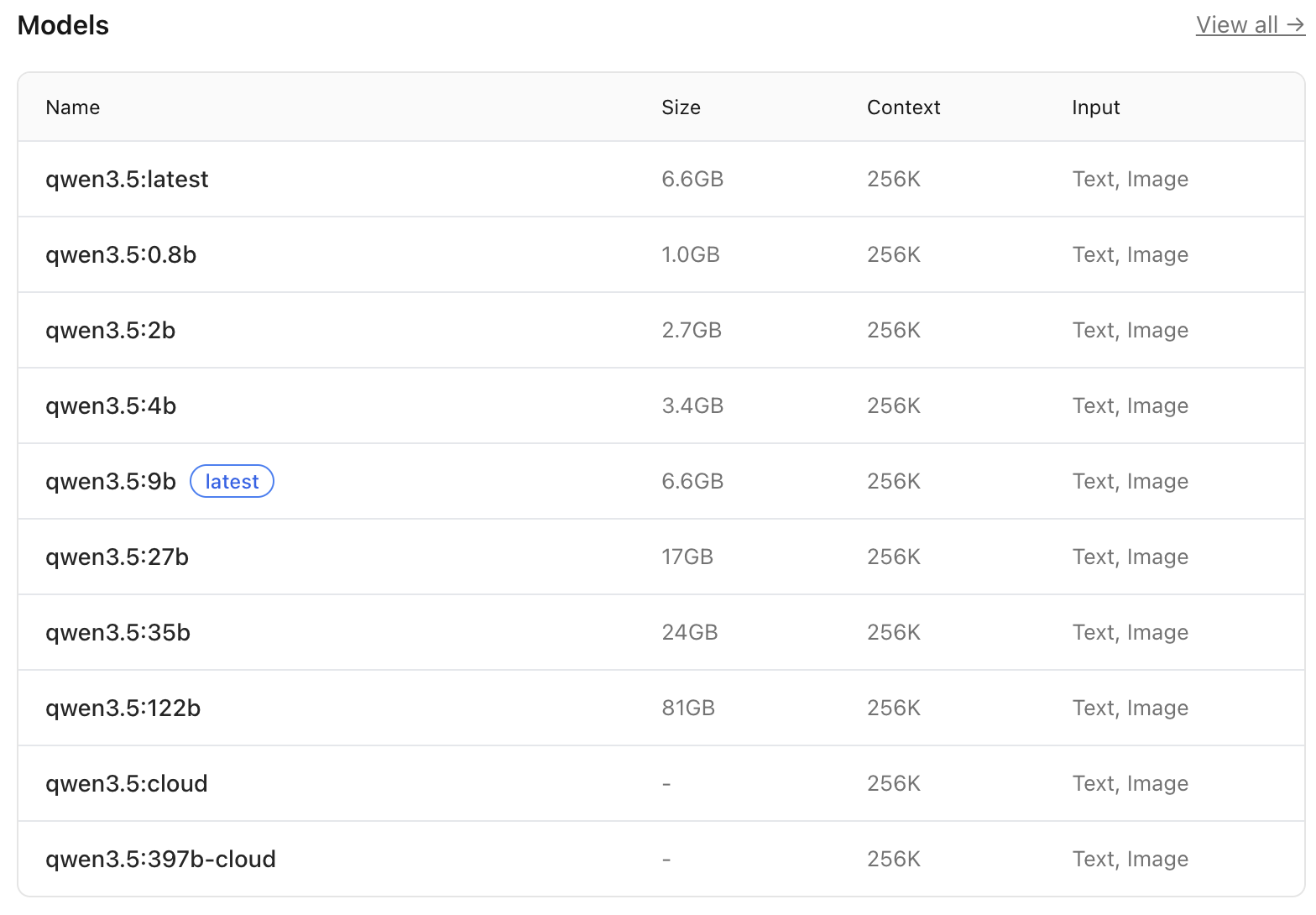
根据电脑的硬件配置选择合适的量化模型
对于 MacBook Pro M4 16G 的配置,推荐选择 qwen3.5:9b 模型
模型镜像模型镜像是由大模型文件按照指定的格式打包的制品。
下载模型下载查询到的指定模型,在终端执行下载命令
ollama pull qwen3.5:9b
输出如下:
% ollama pull qwen3.5:9bpulling manifestpulling dec52a44569a: 100% ██████████████████████████████████▏ 6.6 GBpulling 7339fa418c9a: 100% ██████████████████████████████████▏ 11 KBpulling 9371364b27a5: 100% ██████████████████████████████████▏ 65 Bpulling be595b49fe22: 100% ██████████████████████████████████▏ 475 Bverifying sha256 digestwriting manifestsuccess
直接执行 ollama run qwen3.5:9b时,如果模型不存在也会自动下载。
查看本地已下载的模型通过 ollama pull 和 ollama run 运行的模型会下载到本地,可以通过 ollama list 来查看本地已经下载的模型列表
% ollama listNAME ID SIZE MODIFIEDqwen3.5:9b 6488c96fa5fa 6.6 GB 20 minutes ago
查看本地模型详情模型详情可以在 Ollama Web页面上查看,如 https://ollama.com/library/qwen3.5
对于下载到本地的模型,也可以查看模型详情:
ollama show qwen3.5:9b
输出样例:
% ollama show qwen3.5:9b Model architecture qwen35 parameters 9.7B context length 262144 embedding length 4096 quantization Q4_K_M requires 0.17.1 Capabilities completion vision tools thinking Parameters presence_penalty 1.5 temperature 1 top_k 20 top_p 0.95 License Apache License Version 2.0, January 2004 ...
运行模型基于模型镜像运行模型,请阅读 模型服务[1] 章节
删除本地模型模型下载数量较多时,会消耗较多的磁盘存储。通过删除历史版本或者不需要的模型可以释放存储空间
对于不需要的模型,可以使用 ollama rm 命令删除
% ollama rm qwen3.5:9b
模型复制模型复制是为已有模型创建一个完全相同的副本并赋予新名称
ollama cp qwen3.5:9b my-custom-qwen3.5:9b
模型推送可以将本地模型推送到远程仓库
% ollama push qwen3.5:9b Pushing model qwen3.5:9b... Pushed model qwen3.5:9b Successfully pushed model qwen3.5:9b
运行模型模型服务是由模型镜像启动的进程,用于处理用户请求。
运行模型在终端直接执行如下命令即可运行命令,如果模型不存在也会自动下载该模型。
ollama run qwen3.5:9b
运行成功后,就可以进行对话了。
如果想退出对话,使用 Ctrl + d快捷键, 或者输入 /bye
% ollama run qwen3.5:9b>>>>>> 你好Thinking...Thinking Process:1. **Analyze the Request:** * Input: "你好" (Nǐ hǎo) - Chinese for "Hello". * Intent: Greeting. * Language: Chinese. * Expected Response: A polite greeting in return, offering assistance.2. **Determine the appropriate tone:** * Friendly, polite, helpful. * Match the user's language (Chinese).3. **Draft possible responses:** * Simple: 你好!有什么我可以帮你的吗? (Hello! Is there anything I can help you with?) * Warm: 你好呀!很高兴见到你。今天有什么我可以帮你的吗? (Hello! Nice to meet you. Is there anything I can help you with today?) * Professional: 您好,我是 Qwen3.5,很高兴为您服务。请问有什么可以帮您? (Hello, I am Qwen3.5, glad to serve you. How may I assist you?)4. **Select the best response:** * Since I'm an AI assistant, being polite and offering help is standard. * Keep it natural. * "你好!有什么我可以帮你的吗?" is good. * Maybe add a bit of warmth.5. **Final Polish (Internal Monologue):** * The user said "你好". I should reply with "你好" and offer help. * Let's keep it concise but friendly.6. **Final Output Construction:** * "你好!有什么我可以帮你的吗?" or "你好呀!欢迎使用我的服务,请问今天有什么可以帮您的?" * Let's go with a balanced, friendly version. * Selected: 你好!很高兴为你服务。今天有什么我可以帮助你的吗?7. **Output Generation** (matching the thought process)....done thinking.你好!很高兴见到你。👋有什么我可以帮你的吗?无论是回答问题、创作文字,还是协助分析文档,我都在这里随时待命哦。>>> Send a message (/? for help)
禁用思考方法1: 启动时添加 --think=false 参数如果不想启动思考,你可以使用 --think=false 参数来禁用它。
% ollama run qwen3.5:9b --think=false>>> 早上好早上好!☀️ 新的一天开始了,愿你心情愉快、充满活力。有什么我可以帮你的吗?无论是回答问题、寻找灵感,还是需要一点小建议,随时告诉我哦!😊
方法2: 添加 /set nothink 命令在聊天窗口中,输入 /set nothink 命令来禁用思考。
% ollama run qwen3.5:9b>>> /set nothinkSet'nothink' mode.>>> 你好你好!有什么我可以帮你的吗?😊
方法3: 通过 API 调用控制在使用 Ollama 的 API 进行聊天请求时,可以在请求体中设置 "think": false 来关闭思考。
{ "model":"qwen3.5:9b", "messages":[ {"role":"user","content":"你好"} ], "think":false}
查看运行中的模型通过 ollama run 运行启动中的模型,通过 ollama ps命令可以查看
% ollama psNAME ID SIZE PROCESSOR CONTEXT UNTILqwen3.5:9b 6488c96fa5fa 8.6 GB 100% GPU 4096 4 minutes from now
停止模型通过 ollama stop 命令可以停止模型
% ollama stop qwen3.5:9b
引用链接[1] 模型服务: https://cncfstack.com/p/ollama/docs/3000.ai-models/3010.%E6%A8%A1%E5%9E%8B%E9%95%9C%E5%83%8F%E6%9C%8D%E5%8A%A1%E4%BB%93%E5%BA%93/3030.模型服务/_index.md