在“智能矿山”与“互联矿山”的宏大叙事下,数字化转型已不再是矿业的选择题,而是生存题 。然而,汹涌的数据浪潮并未直接转化为生产力的提升。地质勘探、采掘、运输、选矿、安全监控等环节产生了海量异构数据,它们被禁锢在独立的业务系统中,形成了坚固的“数据孤岛” 。数据标准不一、质量参差不齐、关联分析困难,使得数据无法自由流动,更遑论支撑全局性的智能决策 。
数据中台,正是破解这一困局的核心战略。它并非简单的技术堆砌,而是一种将数据作为核心资产进行统一管理、治理、整合与服务化的机制与能力中心 。它如同一座桥梁,连接着底层庞杂的数据源与上层多变的业务应用,旨在将沉睡的数据唤醒,锻造成驱动业务创新与精细化运营的强大引擎 。本文旨在深入剖析矿山数据中台的构建逻辑,为制造业同仁提供一份从顶层设计到价值实现的系统性指南。
一、矿山数据中台的顶层设计与架构哲学1.核心理念:从“数据孤岛”到“数据资产”的思维跃迁
构建矿山数据中台的首要任务,是实现思维模式的根本转变:必须将数据从业务流程的“副产品”提升至企业级的“战略资产” 。中台的核心使命,便是围绕这一资产进行全生命周期的管理,实现其价值最大化。这意味着数据能力需要从各个业务部门的“竖井”中沉淀下来,形成可复用、可共享、可快速响应业务需求的中央数据能力层 。其最终目标是敏捷地赋能前端业务,而非成为新的技术壁垒。
2.关键架构组件剖析

一个稳健的矿山数据中台通常遵循分层解耦的设计原则,其核心架构可解构为三大组件:
数据集成层 (Data Integration Layer):这是中台的基石,负责“收水”。矿山数据源极其广泛,涵盖了井下传感器的实时流数据、PLC/DCS系统的生产过程数据、地测系统中的地理空间数据、ERP/MES中的运营管理数据等 。该层需要具备强大的多源异构数据接入能力,通过ETL(抽取、转换、加载)工具处理批量数据,并借助实时流处理框架(如Apache Kafka, Apache Flink)捕获毫秒级的实时数据流 。对OPC UA、Modbus、MQTT等工业协议的 natively 支持与解析是其关键能力之一。
数据存储与计算层 (Data Storage and Computation Layer):这是中台的“水库”与“引擎”,负责“蓄水”与“活水”。鉴于矿山数据的多样性——包含结构化的生产报表、半结构化的设备日志以及非结构化的地质图件——单一的存储方案难以应对。因此,采用“数据湖+数据仓库”的混合架构成为主流选择,数据湖负责原始数据的海量存储,数据仓库则提供高性能的结构化数据查询与分析 。计算引擎(如Apache Spark)则需同时支持批处理与流处理,而Lambda架构等设计模式可有效平衡对历史数据进行深度分析和对实时数据进行快速响应的需求 。
数据服务与治理层 (Data Service and Governance Layer):这是中台价值输出的核心,负责“供水”。该层将经过处理、整合、建模后的数据,以标准化的API(应用程序接口)形式,封装成统一、可复用的数据服务,供上层业务应用(如生产调度、设备预警、安全监控等)按需调用 。与服务化相伴相生的是严格的数据治理。这包括建立统一的数据标准、保障数据质量、实施精细化的访问控制与安全策略,以及构建全面的元数据管理体系,确保每一份数据资产都清晰、可信、可用 。
二、攻坚克难:矿山特殊环境下的技术实现路径
矿山独特的作业环境,对数据中台的建设提出了远超常规场景的严苛挑战。
1.边缘侧数据采集与处理:应对恶劣环境与网络限制
矿区地理位置偏远、井下环境恶劣(高温、高湿、粉尘、振动)、网络连接不稳定甚至频繁中断,是数据采集面临的普遍难题 。将所有数据实时传输至云端或中央数据中心既不现实也不经济。因此,“边缘计算”成为必然选择。
硬件选型标准:部署在作业现场的边缘计算网关及服务器,其硬件选型必须遵循工业级甚至军用级标准。这包括支持宽温工作(如-40℃至+85℃)、具备高防护等级(IP65或更高)的坚固外壳以防尘防水、采用无风扇散热设计以应对粉尘环境,并配备冗余电源和抗振动设计,确保在极端条件下的7x24小时稳定运行 。
工业协议实时采集与转换:边缘侧的核心任务之一是协议的“终结”与数据的“新生”。工业智能网关需内置丰富的工业协议栈,能够直接与现场的PLC、传感器等设备通信,实时采集Modbus、OPC UA、MQTT等协议数据 。最佳实践是“边缘转换,按需提供” :在边缘节点上将各种私有或标准协议统一转换为标准化的数据模型(如OPC UA或MQTT),并进行初步的数据清洗、聚合与计算。这不仅大幅降低了对骨干网络带宽的占用,也保证了关键业务逻辑的低延迟响应 。
2.多源异构数据的融合建模:构建统一语义视图
矿山数据中台面临的另一大挑战,是如何融合地质空间数据、设备传感器数据和生产运营数据这三类截然不同但又紧密关联的数据 。它们在数据结构、时间与空间尺度、语义内涵上存在巨大鸿沟。
解决之道在于构建统一的语义数据模型,而本体论(Ontology)为此提供了强大的理论与技术支撑 。通过引入地学本体(Geo-ontology)等领域知识库,我们可以用一种形式化、机器可理解的语言,来定义矿山领域的核心概念(如矿体、断层、设备、工序)及其之间的复杂关系 。基于此本体,可将不同来源的数据映射到一个统一的语义框架下,消除语义歧义,实现从“数据集成”到“知识融合”的跨越,为后续的跨系统、跨领域深度分析奠定坚实基础 。
三、从数据到智慧:驱动智能决策的闭环链路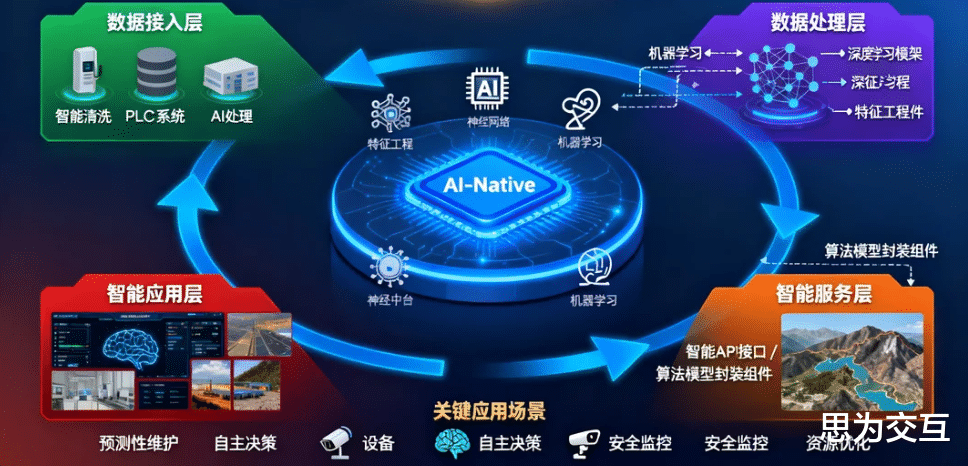
数据中台的终极价值,在于驱动智能决策,形成数据驱动的业务闭环。
1.架构整合模式:数据中台与智能决策系统的无缝对接
数据中台是孕育高级分析与人工智能应用的沃土 。为了实现二者的无缝对接,架构上应采用“AI-Native”的整合模式。这意味着AI能力并非作为外部系统调用数据中台的服务,而是深度嵌入到数据中台的各个环节:在数据接入时进行智能清洗,在数据处理时运用机器学习模型进行特征工程,在数据服务层直接封装算法模型为智能API 。这种原生融合的架构,确保了从数据到洞察再到决策的链路最短、效率最高。
2.智能应用赋能:从预测性维护到自主运营
在坚实的架构之上,一系列高价值的智能应用得以实现:
预测性分析与优化:通过融合设备运行的实时传感器数据、历史维修记录与生产计划数据,可以构建精准的设备健康度评估与故障预测模型,实现从“计划性维修”到“预测性维护”的转变,极大提升设备利用率并降低运维成本 。同理,通过对地质、采掘与选矿数据的综合分析,可以优化采掘计划与配矿方案,实现资源利用率的最大化 。
自主决策模型:更进一步,智能决策系统可以从“辅助决策”走向“自主决策”。例如,当安全监控系统通过视频分析与传感器数据识别出潜在风险时,自主决策模型可直接触发报警、停机甚至人员撤离指令 。这构成了“感知-分析-决策-执行”的智能闭环,是实现矿山少人化乃至无人化运营的终极形态 。
四、价值量化与持续演进:衡量成功并规划未来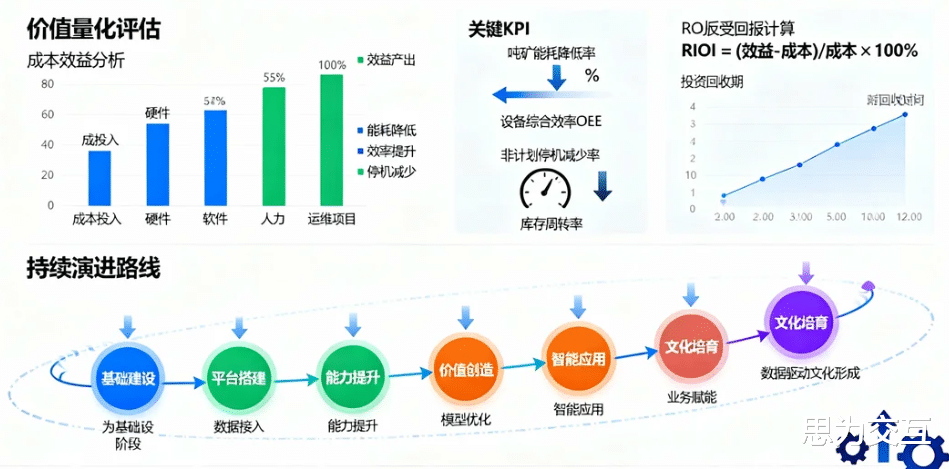
数据中台是一项重大的战略投资,对其效益的科学评估至关重要。
1.成本效益评估与ROI量化模型
在项目启动前,就应建立清晰的成本效益评估框架 。
成本(Cost):需全面核算,包括硬件采购、软件许可、平台开发、人力投入等直接成本,以及后续的运维、培训等间接成本 。
效益(Benefit):效益的量化是核心。应将“提质增效、降本减存、安全环保”等宏观目标,分解为可量化的关键绩效指标(KPI),例如:吨矿综合能耗降低率、设备综合效率(OEE)提升率、非计划停机时间减少率、备品备件库存周转率等 。
投资回报率(ROI)与投资回收期(Payback Period):基于清晰的成本与效益量化,可以计算项目的ROI与投资回收期,为决策层提供直观的判断依据 。
2.演进路线:构建可持续发展的数据能力
数据中台的建设绝非一蹴而就的工程项目,而是一项需要长期投入、持续演进的能力建设过程 。技术栈需要不断迭代升级,数据治理体系需要随业务发展而持续完善,数据模型与算法应用也需要不断优化 。它的成功,最终体现在能否在企业内部培育出一种以数据为基础进行思考、管理和决策的文化。
结论总而言之,矿山数据中台是应对行业数字化转型挑战的系统性解决方案。它不仅是一套技术架构,更是一种数据驱动的运营哲学。通过打破数据壁垒,构建统一、高质量、服务化的数据资产体系,数据中台为上层的预测性分析、全局优化与自主决策等高级智能应用提供了坚实的基础。它将是通往更高效、更安全、更绿色智慧矿山之路上,不可或缺的、最为关键的一步。