
大家好,我是29岁的小米,一名积极活泼、热爱分享技术的开发者。今天,我们来聊聊分布式系统中的一个重要话题——分布式一致性,特别是数据库和Redis的一致性问题。希望这篇文章能帮助你更好地理解并应用这些概念。
在互联网高速发展的今天,高效的数据读取是每个系统都必须面对的问题。为了实现高效读取,很多系统都采用了全量缓存的策略,即所有数据都存储在缓存里,所有的读服务请求都不再降级到数据库,完全依赖缓存。这种方式在某些场景下能有效解决因降级到数据库导致的毛刺问题,但同时也带来了新的挑战,特别是在数据更新时的分布式事务问题。今天,我们就来探讨如何通过订阅数据库的Binlog来实现数据同步,从而解决这些问题。
全量缓存:高效读取的利器全量缓存的优势
全量缓存策略意味着将所有数据都放在缓存中,而不是只缓存部分热点数据。这种方式的好处显而易见:
高效读取:所有请求都直接命中缓存,极大地提高了读取速度,减少了数据库的访问压力。
稳定性:避免了因数据库访问带来的毛刺问题,使系统更加稳定。
然而,全量缓存也带来了一些新的挑战,尤其是如何保证缓存和数据库之间的一致性。
全量缓存的一致性挑战
在全量缓存策略下,任何数据更新都必须同时更新缓存和数据库。这种情况下,分布式事务的问题就显得尤为突出,因为一旦更新操作在缓存和数据库之间不同步,就会导致数据不一致。
订阅数据库的Binlog实现数据同步为了保证缓存和数据库的一致性,我们可以采用订阅数据库的Binlog的方式来实现数据同步。Binlog是MySQL等数据库用来记录所有数据库表变化的日志,通过订阅Binlog,我们可以实时获取数据库的所有变更,并将这些变更同步到缓存中。
Binlog的工作原理
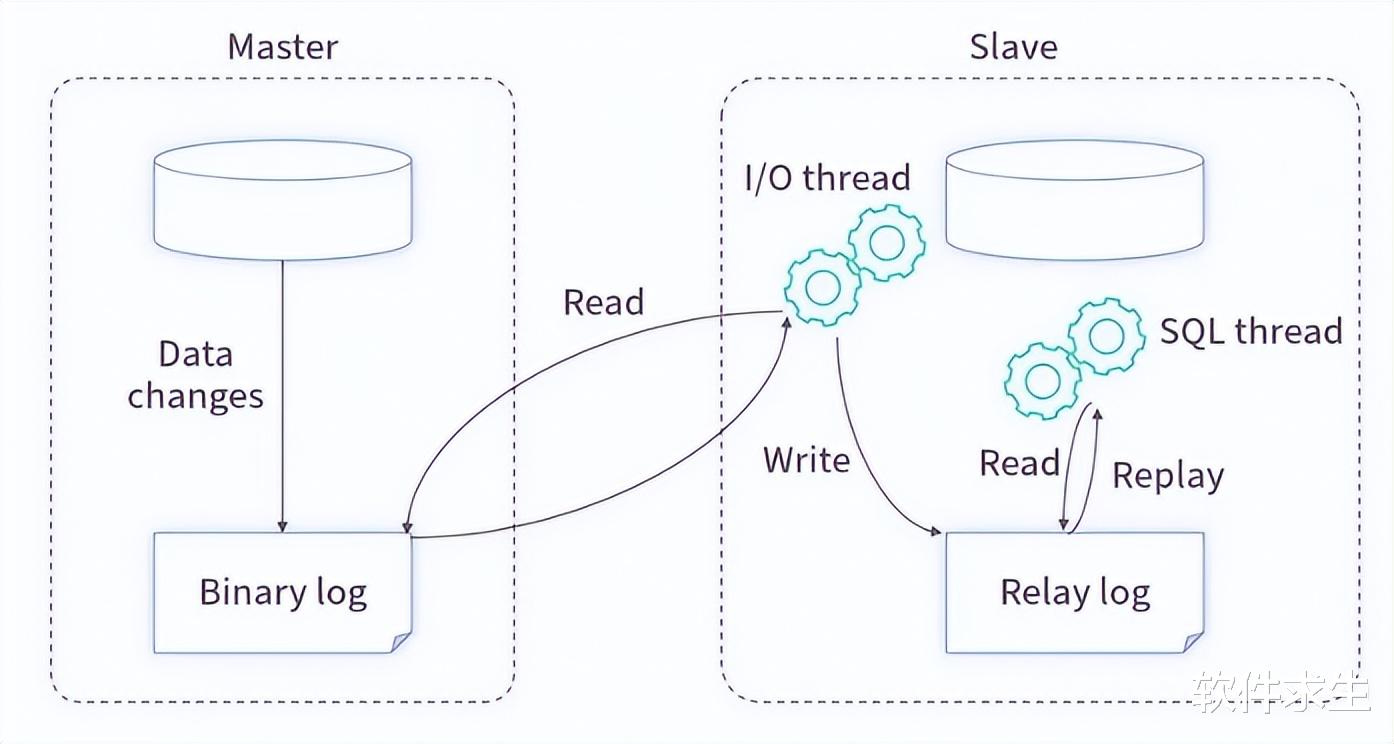
Binlog记录了所有对数据库的修改操作,通过订阅Binlog,我们可以获取到这些操作的详细信息。很多开源工具(如阿里的Canal)可以模拟主从复制的协议,通过读取主数据库的Binlog文件来获取主库的所有变更。这些工具开放了各种接口供业务服务获取数据,并将其写入缓存。
实现步骤
挂载Binlog中间件:将Binlog中间件(如Canal)挂载至目标数据库上,实时获取数据库的变更数据。
解析变更数据:对获取的变更数据进行解析,得到具体的修改操作。
更新缓存:将解析后的数据写入缓存,保证缓存中的数据与数据库一致。
优点分析
采用Binlog订阅实现数据同步,有以下几个优点:
大幅提升读取速度:所有读取操作都从缓存中获取,减少了数据库的负担。
降低延迟:实时同步数据,保证缓存中的数据是最新的。
解决分布式事务问题:Binlog的主从复制基于ACK机制,可以有效解决分布式事务的问题。
确保数据一致性:如果同步缓存失败,未被确认的Binlog会被重复消费,最终保证数据写入缓存中。
缺点分析
尽管采用Binlog订阅有很多优点,但也存在一些不可避免的缺点:
增加系统复杂度:引入Binlog中间件和同步机制,增加了系统的复杂度。
消耗缓存资源:所有数据都存储在缓存中,需要更多的缓存资源。
需要筛选和压缩数据:为了减少缓存占用,需要对数据进行筛选和压缩。
极端情况数据丢失:在极端情况下,可能会出现数据丢失的问题。
异步校准方案:补齐数据的一种方式为了进一步保证数据的一致性,我们可以采用异步校准方案来补齐数据。这种方案的核心思想是定期校验数据库和缓存中的数据是否一致,对于不一致的数据进行补齐。

异步校准的步骤
数据校验:定期对数据库和缓存中的数据进行校验,发现不一致的数据。
数据补齐:对于不一致的数据,通过异步方式将正确的数据写入缓存,保证数据一致性。
优缺点分析
异步校准方案有以下优点和缺点:
优点:
进一步保证数据一致性:通过定期校验和补齐数据,进一步保证了数据的一致性。
降低数据库压力:异步校准在非高峰期进行,避免了对数据库的实时压力。
缺点:
消耗数据库性能:定期校验和补齐数据,会增加数据库的负担。
复杂度增加:引入异步校准机制,增加了系统的复杂度。
线上环境的注意事项在实际应用中,线上环境的稳定性至关重要。因此,在引入Binlog订阅和异步校准方案时,需要注意以下几点:
记录日志:在初期阶段,详细记录日志以排查潜在问题。
逐步优化:在初期阶段,重在发现问题和记录日志,后续逐步优化,不可本末倒置。
监控报警:建立完善的监控和报警机制,及时发现并处理异常情况。
总结全量缓存策略通过将所有数据存储在缓存中,实现了高效的读取操作,避免了降级到数据库带来的毛刺问题。然而,在数据更新时,如何保证缓存和数据库之间的一致性是一个挑战。通过订阅数据库的Binlog,我们可以实时获取数据库的变更数据,并将其同步到缓存中,从而有效解决分布式事务问题,保证数据一致性。
尽管这一方案存在一定的复杂度和资源消耗,但通过合理的设计和优化,可以有效提升系统的性能和稳定性。希望这篇文章能为你在实现分布式一致性方面提供一些思路和参考。
END感谢你的阅读,如果你有任何疑问或需要进一步的讨论,欢迎在评论区留言。让我们一起学习,一起进步!
