本文根据完整的基准测试,将Achronix Semiconductor公司推出的Speedster7t FPGA与GPU解决方案进行比较,在运行同一个Llama2 70B参数模型时,该项基于FPGA的解决方案实现了超越性的LLM推理处理。
Based on a complete benchmark, this paper compares Achronix Semiconductor's Speedster7t FPGA with a GPU solution that enables superior LLM inference processing while running the same Llama2 70B parameter model.
采用 FPGA 器件来加速LLM 性能,在运行 Llama2 70B 参数模型时,Speedster7t FPGA 如何与 GPU 解决方案相媲美?证据是令人信服的——Achronix Speedster7t FPGA通过提供计算能力、内存带宽和卓越能效的最佳组合,在处理大型语言模型(LLM)方面表现出色,这是当今LLM复杂需求的基本要求。
Using FPGA devices to accelerate LLM performance, how does the Speedster7t FPGA compare to GPU solutions when running the Llama2 70B parametric model? The evidence is compelling - Achronix Speedster7t FPGas excel at handling large language models (LLMS) by providing the best combination of computing power, memory bandwidth, and superior energy efficiency, an essential requirement for today's complex LLM demands.
像 Llama2 这样的 LLM 的快速发展正在为自然语言处理(NLP)开辟一条新路线,有望提供比以往任何时候都更像人类的交互和理解。这些复杂的 LLM 是创新的催化剂,推动了对先进硬件解决方案的需求,以满足其密集处理需求。
The rapid development of LLMS like Llama2 is opening up a new route for natural language processing (NLP), promising to provide more human-like interaction and understanding than ever before. These complex LLMS are catalysts for innovation, driving the need for advanced hardware solutions to meet their intensive processing needs.
我们的基准测试突出了 Speedster7t 系列处理 Llama2 70B 模型复杂性的能力,重点关注 FPGA 和 LLM 性能。这些测试(可根据要求提供结果)显示了Achronix FPGA对于希望将LLM的强大功能用于其NLP应用程序的开发人员和企业的潜力。这些基准测试展示了 Speedster7t FPGA 如何超越市场,提供无与伦比的性能,同时降低运营成本和环境影响。
Our benchmark tests highlight the Speedster7t family's ability to handle the complexity of the Llama270B model, with a focus on FPGA and LLM performance. These tests, with results available on request, show the potential of Achronix FPGas for developers and businesses looking to leverage the power of LLM for their NLP applications. These benchmark tests demonstrate how Speedster7t FPgas outperform the market, delivering unmatched performance while reducing operating costs and environmental impact.
Llama2 70B LLM 运行
The Llama2 70B LLM runs
2023 年 7 月,Microsoft 和 Meta 推出了他们的开源 LLM,Llama2 开创了 AI 驱动语言处理的新先例。Llama2 采用多种配置设计,以满足各种计算需求,包括 700 亿、130 亿和 700 亿个参数,使其处于 LLM 创新的最前沿。Achronix和我们的合作伙伴 Myrtle.ai 对700亿参数的Llama2模型进行了深入的基准分析,展示了使用Speedster7t FPGA进行LLM加速的优势。
In July 2023, Microsoft and Meta launched their open source LLM, Llama2, which sets a new precedent for AI-driven language processing. The Llama2 is designed in multiple configurations to meet a variety of computing needs, including 70 billion, 13 billion and 70 billion parameters, putting it at the forefront of LLM innovation. Achronix and our partner Myrtle.AI conducted an in-depth benchmarking analysis of the 70 billion parameter Llama2 model, demonstrating the advantages of using Speedster7t FPGas for LLM acceleration.
Speedster7t FPGA 与业界领先的 GPU 对比
Speedster7t FPGas compared to industry-leading Gpus
我们在Speedster7t FPGA 上测试了 Llama2 70B 模型的推理性能,并将其与领先的 GPU 进行了比较。该基准测试是通过对输入、输出序列长度 (1,128) 和批处理大小 =1 进行建模来完成的。结果表明,Speedster7t AC7t1500在LLM处理中的有效性。
We tested the inference performance of the Llama270B model on a Speedster7t FPGA and compared it to leading Gpus. This benchmark is done by modeling the input and output sequence length (1,128) and batch size =1. The results show the effectiveness of Speedster7t AC7t1500 in LLM processing.
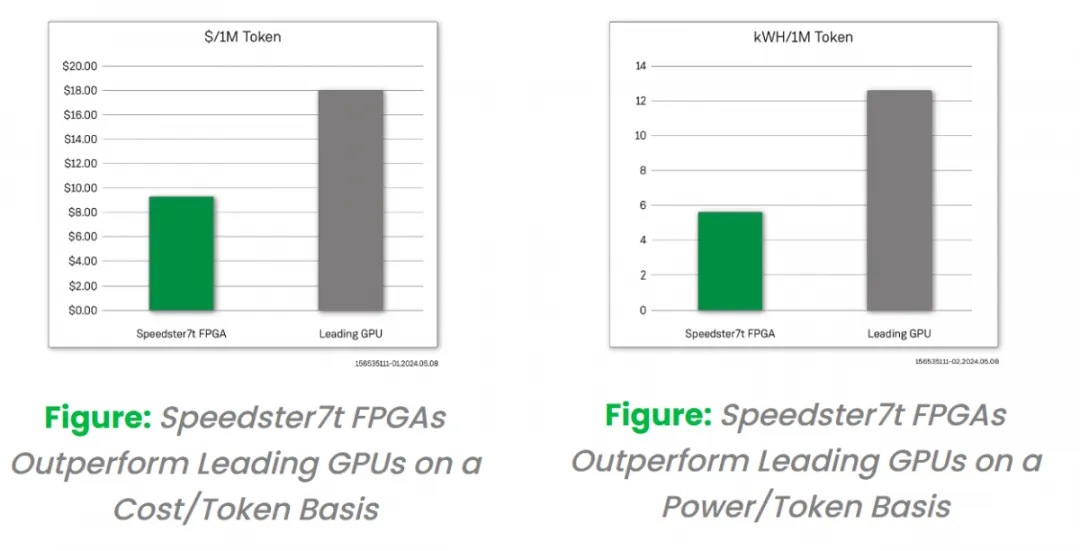
FPGA 成本基于由 Speedster7t FPGA 提供支持的 VectorPath 加速卡的标价。同样,我们在此分析中使用了可比GPU卡的标价。使用这些成本信息和每秒产生的输出令牌数量,我们计算出基于 FPGA 的解决方案的 $/token 提高了 200%。除了成本优势外,在比较 FPGA 和 GPU 卡的相对功耗时,我们观察到与基于 GPU 的解决方案相比,产生的 kWh/token 提高了 200%。这些优势表明 FPGA 如何成为一种经济且能效高效的 LLM 解决方案。
The FPGA cost is based on the sticker price of the VectorPath accelerator card powered by the Speedster7t FPGA. Again, we used sticker prices for comparable GPU cards in this analysis. Using this cost information and the number of output tokens generated per second, we calculated a 200% improvement in $/token for the FPGA-based solution. In addition to the cost advantages, when comparing the relative power consumption of FPgas and GPU cards, we observed a 200% increase in kWh/token generation compared to GPU-based solutions. These advantages show how FPgas can be an economical and energy efficient LLM solution.
Achronix Speedster7t系列FPGA旨在优化LLM操作,平衡LLM硬件的关键要求,包括:
The Achronix Speedster7t series FPGA is designed to optimize LLM operation and balance the key requirements of LLM hardware, including:
高性能计算 – 具有高性能计算能力的尖端硬件对于管理 LLM 推理核心的复杂矩阵计算至关重要。
High Performance Computing -Cutting-edge hardware with high performance computing capabilities is essential to manage the complex matrix calculations at the heart of LLM reasoning.
高带宽内存 – 高效的 LLM 推理依赖于高带宽内存,通过模型的网络参数快速馈送数据,而不会出现瓶颈。
High-bandwidth memory -Efficient LLM reasoning relies on high-bandwidth memory to feed data quickly through the network parameters of the model without bottlenecks.
扩展和适应能力 – 现代 LLM 推理需要能够随着模型规模的增长而扩展并灵活适应 LLM 架构的持续进步的硬件。
Scalability and adaptability -Modern LLM reasoning requires hardware that can scale as models grow in size and flexibly adapt to continued advancements in LLM architectures.
高能效处理 –可持续的 LLM 推理需要硬件能够最大限度地提高计算输出,同时最大限度地降低能耗,从而降低运营成本和环境影响。
Energy-efficient processing - Sustainable LLM reasoning requires hardware that can maximize computational output while minimizing energy consumption, thereby reducing operating costs and environmental impact.
Speedster7t FPGA 提供以下功能,以应对实施现代 LLM 处理解决方案的挑战:
The Speedster7t FPGA provides the following capabilities to address the challenges of implementing modern LLM processing solutions:
计算性能 –通过其灵活的机器学习处理器 (MLP) 模块支持复杂的 LLM 任务。
Computational performance -Supports complex LLM tasks with its flexible machine learning processor (MLP) modules.
高 GDDR6 DRAM 带宽 – 确保以 4 Tbps 的内存带宽快速处理大型 LLM 数据集。
High GDDR6 DRAM bandwidth - ensures fast processing of large LLM data sets with a memory bandwidth of 4 Tbps.
大量的 GDDR6 DRAM 容量 –可容纳 Llama2 等扩展的 LLM,每个 FPGA 的容量为 32 GB。
Large GDDR6 DRAM capacity -can accommodate extended LLM such as Llama2, with a capacity of 32 GB per FPGA.
用于 LLM 的集成 SRAM –提供低延迟、高带宽的存储,具有 190 Mb 的 SRAM,非常适合存储激活和模型权重。
Integrated SRAM for LLM -provides low-latency, high-bandwidth storage with 190 Mb of SRAM, ideal for storage activation and model weights.
多种本机数字格式 –适应 LLM 需求,支持块浮点 (BFP)、FP16、bfloat16 等。
A variety of native number formats -suitable for LLM requirements, block floating-point (BFP), FP16, bfloat16, etc.
高效的片上数据传输 – 2D NoC 超过 20 Tbps,简化片上数据流量。
Efficient on-chip data transfer - 2D NoC over 20 Tbps simplifies on-chip data traffic.
扩展横向扩展带宽 –支持多达32个112 Gbps SerDes 满足 LLM 需求,增强连接性。
Scale-out bandwidth - Supports up to 32 112 Gbps SerDes to meet LLM requirements and enhance connectivity.
自适应逻辑级可编程性 –使用 690K 6 输入 LUT 为 LLM 的快速发展做好准备。
Adaptive logic-level programmability - Prepare for the rapid evolution of LLM with 690K 6 input LUT.
针对 LLM 推理优化的 FPGA
FPGA optimized for LLM inference
在快速变化的人工智能和自然语言处理领域,使用 FPGA 而不是 GPU 来加速 LLM 是一个相当新的想法。该基准测试展示了设计人员如何从使用Achronix的FPGA技术中受益。Achronix Speedster7t系列FPGA是这一变化的关键技术,在高性能、高带宽存储器、易于扩展和电源效率之间实现了出色的平衡。
In the rapidly changing field of artificial intelligence and natural language processing, using FPgas instead of Gpus to accelerate LLMS is a fairly new idea. This benchmark demonstrates how designers can benefit from using Achronix's FPGA technology. The Achronix Speedster7t series FPGA is a key technology in this change, providing an excellent balance between high performance, high bandwidth memory, ease of scaling, and power efficiency.
基于详细的基准分析,将 Speedster7t FPGA 与领先的 GPU 在处理 Llama2 70B 模型方面的能力进行比较,结果表明 Speedster7t FPGA 能够提供高水平的性能,同时大大降低运营成本和环境影响,突出了它在未来 LLM 创建和使用中的重要作用。
Based on a detailed benchmarking analysis comparing the Speedster7t FPGA with leading Gpus in processing Llama270B models, the results show that the Speedster7t FPGA can deliver a high level of performance while significantly reducing operating costs and environmental impact. Highlights its important role in the creation and use of LLM in the future.
