【别再死磕完美提示词了,Agent真正的进化靠闭环学习】
快速阅读:与其纠结如何写出完美的 Prompt,不如构建一个能从人类反馈中学习的闭环。对于需要判断力的任务,静态指令注定会过时,真正的效率来自于让 Agent 将团队的审美和判断力转化为可复用的原则。
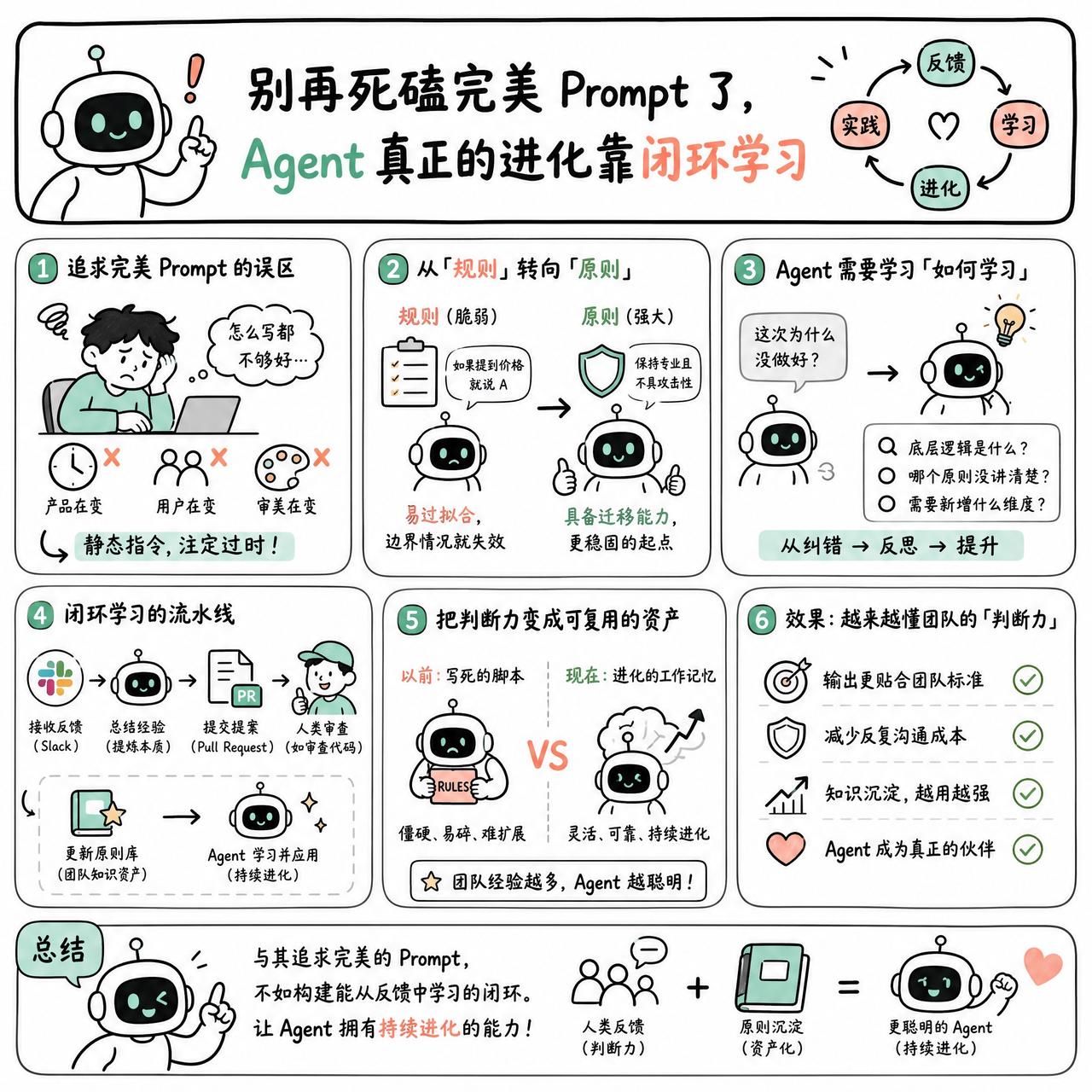
很多人在写 Agent 时会陷入一种误区:试图通过不断精雕细琢 Prompt 来逼近完美。但如果任务涉及判断力,这个目标本身就是错的。产品在变,用户在变,团队的审美也在变,一个月的 Prompt 几乎不可能撑过两个月。
在 Warp 构建处理社交媒体提及的 Agent 时,我们发现很多 Agent 处于一种“差一点就成”的状态:输出看起来不错,但还不足以让人放手。试图通过增加规则来填补这个差距,只会让指令集变得臃肿且机械。
要把 Agent 真正用起来,得把逻辑从“规则”转向“原则”。
规则是脆弱的,比如“如果提到价格就说 A”;而原则是具备迁移能力的,比如“保持专业且不具攻击性”。规则容易过拟合,一旦遇到没写进清单的边界情况,Agent 就会瞬间失效。而原则能给 Agent 提供一个更稳固的逻辑起点。
更有意思的是,Agent 需要学习“如何学习”。
如果只是简单地把反馈变成新规则,Agent 会变得极其笨拙。有网友提到,Agent 往往会把纠错变成一种死板的例外。真正的做法是让 Agent 去思考:这次失败的底层逻辑是什么?是哪个现有原则没讲清楚,还是需要新增一个维度?
我们把这个过程做成了类似代码管理的流水线。Agent 在 Slack 里接收团队的反馈,然后自动总结经验,最后不是直接修改指令,而是提交一个 Pull Request。人类像审查代码一样审查这些原则的变更。
这种方式让原本隐性的“判断力”变成了显性的“资产”。Agent 不再是一个写死的脚本,而是一个随着团队经验增长而不断进化的工作记忆。
x.com/petradonka/status/2054897826149101588