DeepSeek创始人专访:中国的AI不可能永远跟随,需要有人站到技术的前沿
因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏
训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。在多项测评上,DeepSeek V3 达到了开源 SOTA,超越 Llama 3.1 405B,能和 GPT-4o、Claude 3.5 Sonnet 等 TOP 模型正面掰掰手腕——而其价格比 Claude 3.5 Haiku 还便宜,仅为 Claude 3.5 Sonnet 的 9%
在 Chatbot Arena 大模型排行榜上排名第 7,前十名里面,只有它是开源模型,而且是最少限制的 MIT 许可证
2024 年 5 月,DeepSeek 一跃成名。起因是他们发布的一款名为 DeepSeek V2 的开源模型,提供了一种史无前例的性价比,开启了国产大模型的价格战
作为大厂外唯一一家储备万张 A100 芯片的公司,DeepSeek 的很多抉择都与众不同。放弃「既要又要」路线,至今专注在研究和技术,未做 toC 应用的公司,也是唯一一家未全面考虑商业化,坚定选择开源路线甚至都没融过资的公司
DeepSeek 究竟是如何炼成的?36 氪旗下的「暗涌」团队分别在 2023 年 5 月、2024 年 7 月采访了甚少露面的 DeepSeek 创始人梁文锋
这位技术理想主义者,提供了目前中国科技界特别稀缺的一种声音:他是少有的把「是非观」置于「利害观」之前,并提醒我们看到时代惯性,把「原创式创新」提上日程的人
文章转载自「暗涌」,原文作者于丽丽,原文编辑刘旌,Founder Park 转载时做了结构调整
全文链接
.


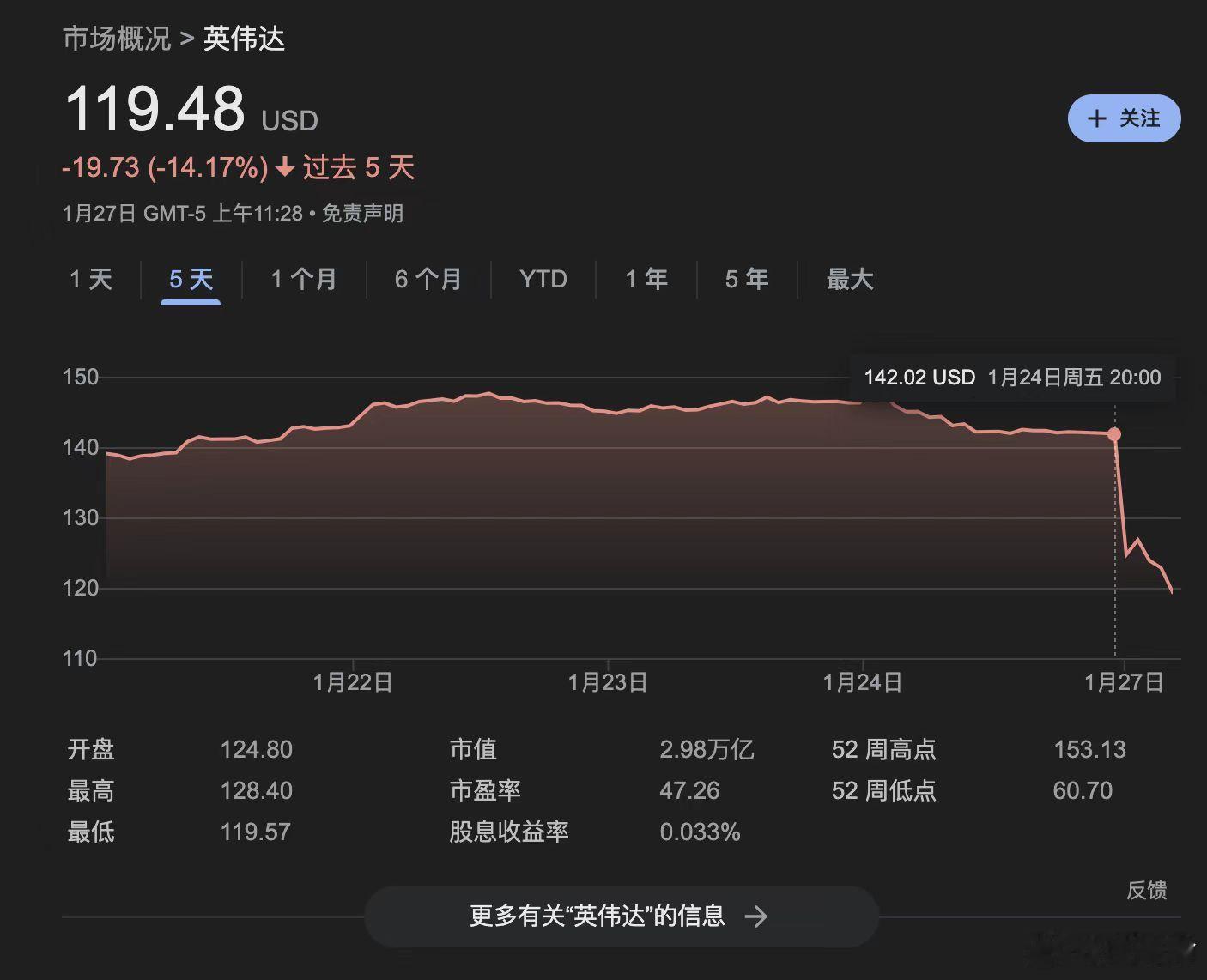
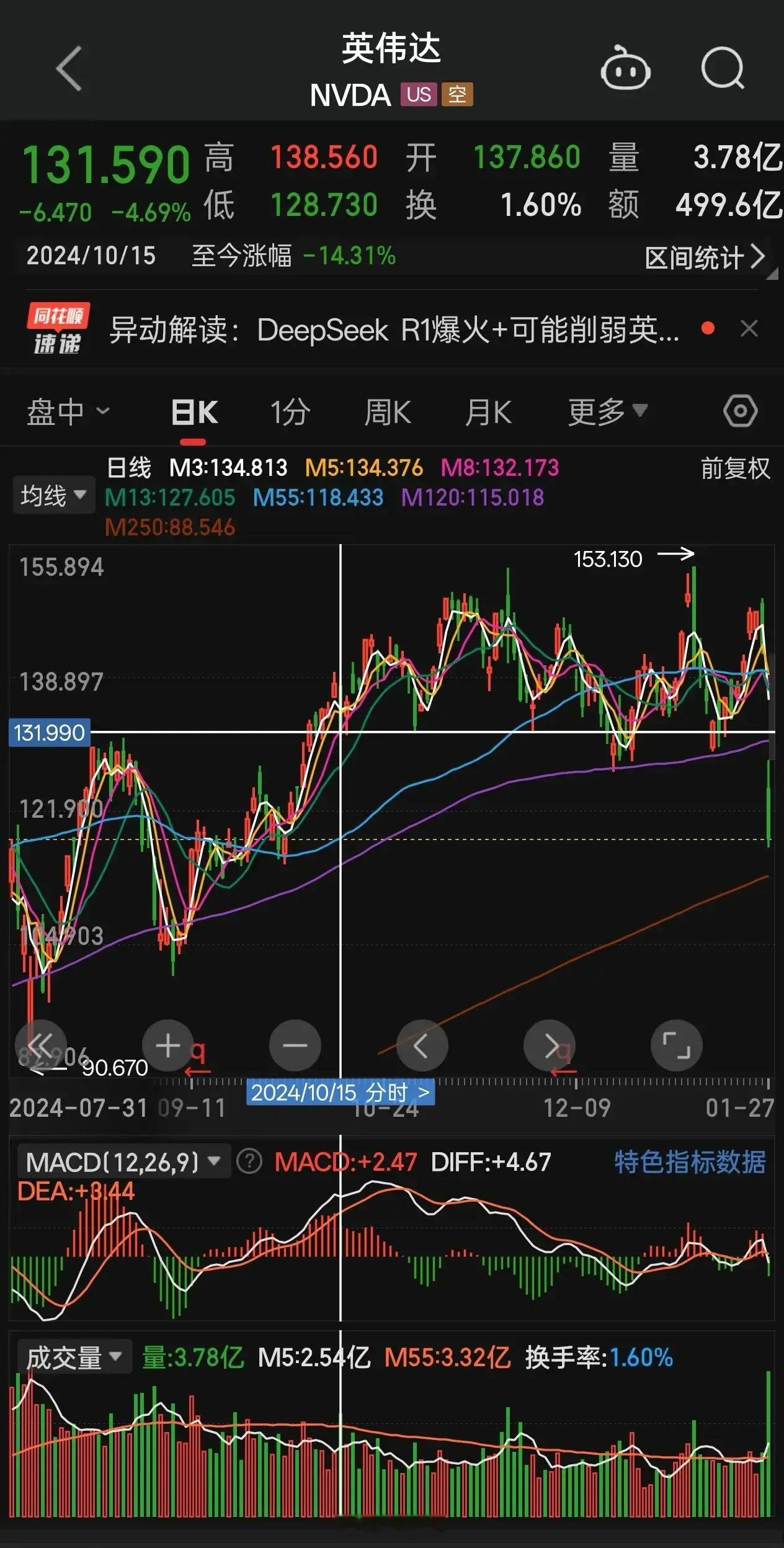


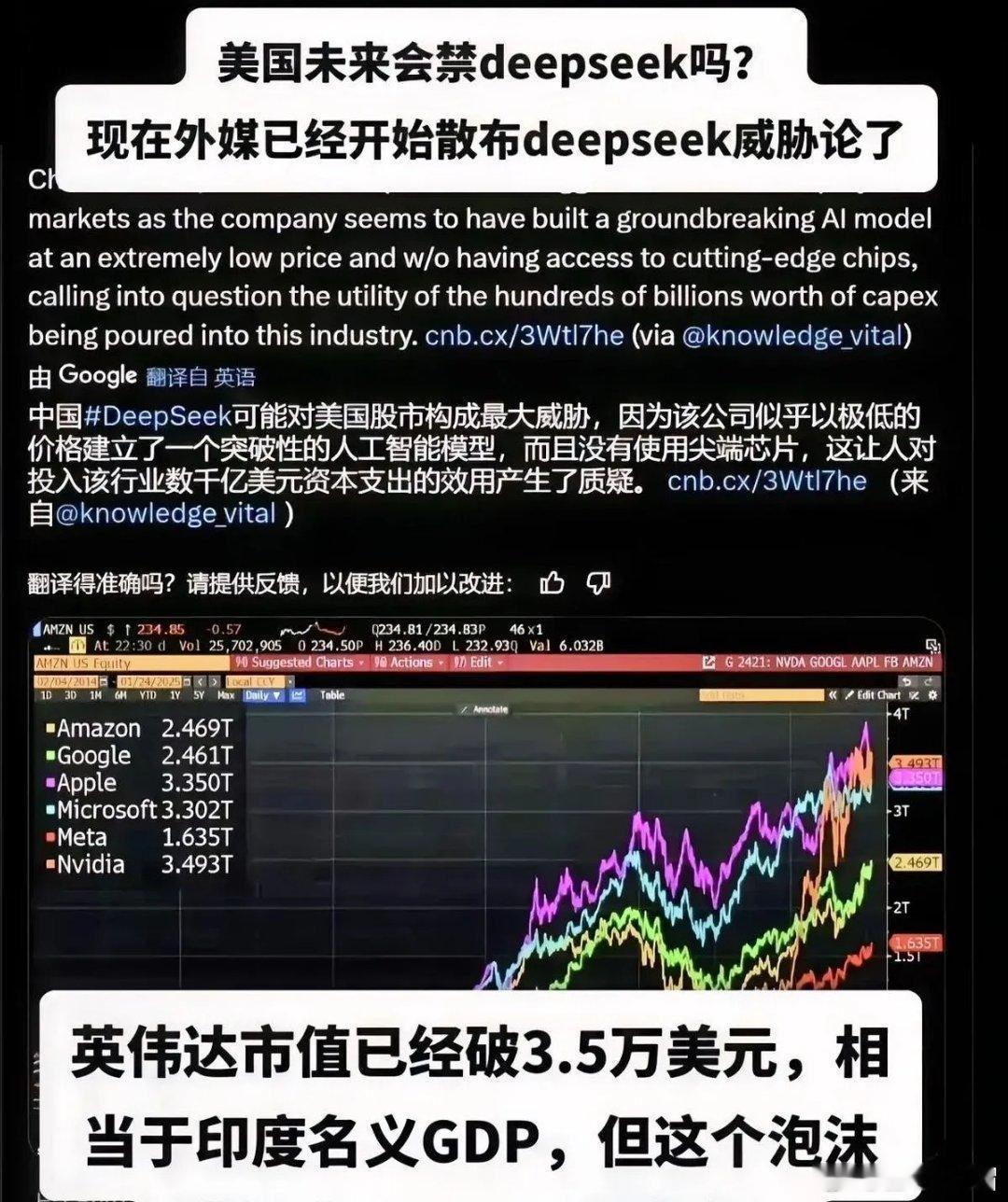

心凉怎暖
[赞][赞][赞]
用户10xxx78
用4台或更多台智能DeepSeek-V3,A组负责尖端提问创新提问,B组负责解答创新,再AB互相学习提升,DeepSeek或别的智能Ai就会产生自我进化,超级无敌人类。